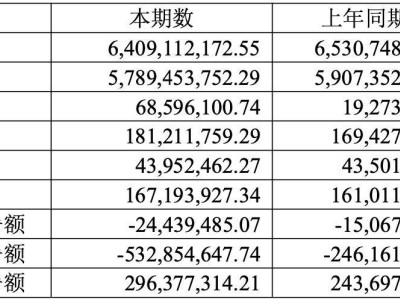
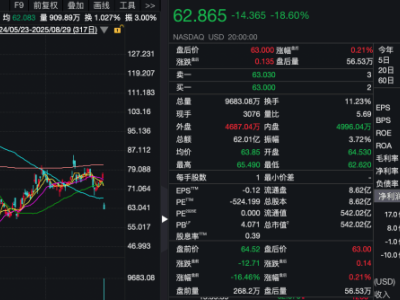
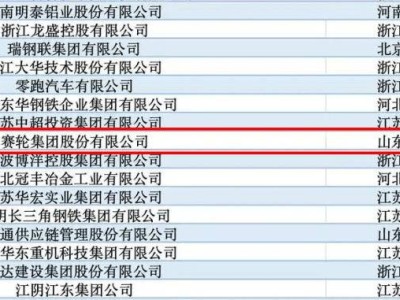
近期,OpenAI的首席执行官奥特曼在一档热门播客中,主动披露了《纽约时报》对OpenAI及其背后的主要投资者微软提起的版权官司。据悉,《纽约时报》指控OpenAI在训练其大型语言模型时,未经授权地使用了该报的内容。尤其令人瞩目的是,奥特曼对于《纽约时报》律师提出的一项新要求表达了强烈不满,即要求OpenAI保留ChatGPT用户及API客户的使用数据。
事实上,近年来,多家出版商已陆续对OpenAI、Anthropic、谷歌和meta等科技巨头提起诉讼,指控它们在训练人工智能模型时,未经授权地使用了受版权保护的作品。这些出版商担忧,人工智能模型可能会削弱甚至取代他们精心制作的版权内容价值。
然而,近期事态的发展似乎对科技公司更为有利。就在本周早些时候,OpenAI的竞争对手Anthropic在与出版商的法律纠纷中取得了关键性的胜利。一位联邦法官裁定,在某些情况下,Anthropic使用书籍来训练其人工智能模型是合法的。这一裁决不仅为Anthropic扫清了障碍,还可能对其他出版商针对OpenAI、谷歌和meta的类似诉讼产生深远的影响。
这一法律纠纷的胜利,无疑为科技公司在面对版权诉讼时提供了更多的法律支持。尽管出版商们对人工智能模型的担忧依然存在,但法律的天平似乎正在逐渐倾斜,给予科技公司更多的操作空间和法律保障。
随着人工智能技术的不断发展和普及,类似的版权诉讼预计将会持续涌现。如何在保护原创内容的同时,又能促进人工智能技术的健康发展,将是未来法律界和科技界需要共同面对的重要课题。