
微软AI研究部门近日宣布,其自主研发的两款AI模型已正式亮相。这两款模型分别是基础模型MAI-1-preview和语音生成模型MAI-Voice-1,标志着微软在AI自研道路上迈出了重要一步。
值得注意的是,MAI-Voice-1的发布与OpenAI新推出的语音模型不谋而合。MAI-Voice-1以其高保真度和表现力强的音频特性,已在Copilot Daily和Podcasts上线,并可在Copilot Labs进行体验。这款模型展现了高度的定制化能力,用户不仅可以选择情绪模式和声音模板,还能从至少40种语体风格中挑选。无论是常见的情绪表达,还是扮演机器人、海盗、吸血鬼等角色,MAI-Voice-1都能对同一段文本进行自主改写和演绎,极具趣味性。
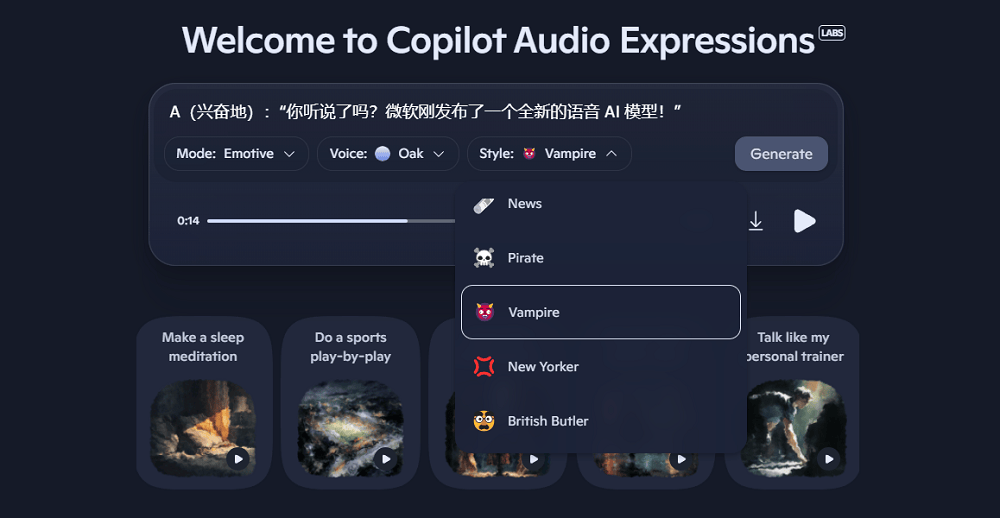
当输入中文文本时,MAI-Voice-1会自动转为英文输出。尽管如此,其生成速度依然迅速,微软表示该模型能在单款GPU上运行,一秒钟即可输出一分钟的音频。
另一方面,MAI-1-preview作为一款混合专家模型,已在约1.5万个英伟达H100 GPU上完成了预训练和后训练。该模型主打指令遵循和日常问题解答等能力,并已在LMArena(大模型竞技场)内进行盲测。虽然目前暂时无法直接体验该模型,但微软透露,未来几周内,MAI-1-preview将应用于Copilot的部分文本场景,以收集反馈并优化用户体验。

微软AI的CEO Mustafa Suleyman在接受专访时表示,AI对微软的业务具有根本性意义,而自研模型计划早在14个月前便已开始。他强调,微软将继续与OpenAI等企业合作,并使用开源模型,但确保始终有选择权至关重要。Suleyman将MAI-1-preview定义为“人格原材料”,意味着该模型在融入产品的过程中,可以展现出各种不同的人格特点。通过后训练、提示词工程等方法,未来的大模型有望涌现出数百万种不同的人格。
在谈到资源投入时,Suleyman表示,微软拥有打造强大模型所需的资源,正在构建世界最大规模的GB200、GB300集群。然而,他强调规模固然重要,但效率同样关键。这意味着要精挑细选高质量训练数据,确保每一次浮点运算和GPU迭代都能发挥最大效用。
Suleyman还分享了对“可解释性”研究的看法。他认为,模型本质是空心的,可解释性研究虽然有意义,但并不会揭示意识的本质。他呼吁业界应谨慎对待AI的发展,提前思考潜在风险,并在发现问题时及时公开、认真对待,推动社区开发者迅速采取行动。
对于微软与OpenAI的关系,Suleyman表示,微软的目标是进一步深化与OpenAI的合作,确保这种关系能持续多年。他强调,双方的合作一直非常成功,未来也将继续合作。
在谈到未来规划时,Suleyman透露,微软AI有一个为期五年的宏大路线图,每个季度都会持续投入。他预计,随着模型的迭代和反馈的收集,性能将显著提升。同时,微软也在积极探索多模态领域,以进一步提升模型的通用性和表现能力。















