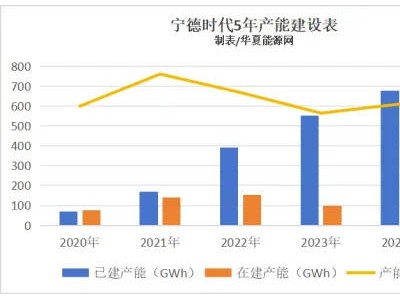
在人工智能大模型产业的快速发展中,算力、算法和数据一直被视为三大核心要素。然而,随着国内AI芯片技术的不断突破以及DeepSeek等产品的出现,算力短板问题逐渐得到缓解。然而,这并不意味着中国大模型的发展之路已经一帆风顺,存力问题正逐渐成为新的焦点。
存力,即数据存储系统,是支撑大模型训练和推理的重要基础设施。随着大模型规模化应用的不断推进,面对万卡集群、万亿参数和海量数据的挑战,传统存储系统的局限性愈发凸显。在数据猿近期举办的线上论坛上,极道科技行业解决方案经理张策和西部数据资深售前工程师芦浩,就存储产业在大模型时代面临的挑战和变革进行了深入探讨。
芦浩指出,大模型规模化商业应用为存储产业带来了四个新趋势:高容量化、多模态化、高速响应化和低成本化。由于大模型在训练过程中会产生大量的中间数据和版本数据,因此存储系统需要具备更高的容量,以容纳PB级甚至EB级的数据量。同时,大模型已经进入多模态阶段,需要存储系统具备跨模态的实时处理能力。高速响应和低成本也是存储系统需要解决的重要问题。
张策则认为,大模型规模化商业应用为存储产业带来了三大变化:超大规模的集群化部署、分布式并行处理和安全可靠。面对超大规模的训练需求,通用的NAS存储已经无法支撑,需要通过集群化、多级部署来构建庞大且灵活的存储系统。同时,分布式并行文件存储系统能够提供可扩展、多节点的能力,应对数据爆发式增长的需求。稳定性和可靠性也是存储系统的基石,无法保证数据安全和服务的稳定性,再高的算力也将被各种故障所吞没。
存储性能直接决定了大模型在训练推理过程中的GPU利用率。对于GPU架构而言,堆叠算力单元不是难事,但当前计算任务主要耗时集中在等待数据从存储系统到达计算单元的过程。较差的存储性能会严重增加GPU闲置时间,导致模型落地困难、业务成本剧增。因此,大模型的发展不仅要求底层存储基础设施具备更高的性能,还倒逼软件定义存储(SDS)向高性能、弹性化与智能化方向迭代。
芦浩表示,市场渴望更高性能、大容量、低成本的技术突破。在性能方面,未来的存储硬件应进一步提升接口带宽,优化存储介质降低延迟,改进存储架构减少数据查找定位等操作时间。同时,由于大模型训练会带来大量的文件读写操作,因此需要对存储硬件有高的IOPs性能突破。在存储容量扩展方面,需要采用Scale Out和Scale Up纵向扩展和横向扩展的存储架构,提高存储容量以容纳海量的数据。在功耗和成本方面,需要大力探索新型的存储介质,如HAMR等。
技术创新之外,存算协同的发展模式也被认为是未来的大势所趋。倪光南院士曾指出,用广义算力去定义一个算力中心才更准确。美国的算力中心存算比为1.11TB/GFlops,而中国约为美国的37.8%。存算一体作为一种新的计算架构,被认为是具有潜力的革命性技术。它通过打破“存储-计算分离”的模式,直接在存储单元内部集成计算单元,支持数据本地化处理,降低网络传输瓶颈。

极道科技作为国内首家提出存管算协同的分布式系统厂商,张策表示,存算协同的算力平台不仅能应对大规模数据集的处理挑战,支持复杂计算任务,还能通过与存储的协同,针对业务类型优化存储配置,进而借助计算集群的智能化加速科研分析效率。在实际运行中,系统中硬件能力存在大量“闲置”,关键在于存储系统无法独立拆解无序堆叠的I/O。通过存算协同机制,可以将关键信息传递给存储系统,使其能够识别并拆解这些无序堆叠的I/O,化无序为有序,并针对不同的I/O进行精准优化。
对存储产业而言,大模型不仅是需求者,更是革新者。大模型能够精准分析每一个计算任务所需的存储带宽、CPU、GPU资源,从而精准判断作业执行周期和完成时间。随着DeepSeek和Manus等超级AI单品的问世,大模型时代正在加速到来。在新的阶段,算效的价值将越发凸显,存储产业作为优化效率的重要基础设施,将扮演比以往更重要的角色,但也势必要承担更大的责任。