阿里巴巴集团于本周二震撼发布其旗舰人工智能模型Qwen 3,标志着AI技术迈入全新纪元。此次升级聚焦于混合推理能力,为用户带来前所未有的智能体验。
Qwen3系列中的旗舰版Qwen3-235B-A22B,虽拥有高达2350亿参数,但运行时仅需激活220亿参数,这一设计巧妙地降低了运营成本,同时性能超越DeepSeek-R1和OpenAI-o1等业界领先模型,成为全球最强大的开源AI模型。
在中国AI领域竞争日益激烈的背景下,本土初创企业DeepSeek的迅速崛起尤为引人注目。今年早些时候,DeepSeek宣布能以更低成本提供高性能模型,挑战西方竞争对手。受此驱动,中国AI市场热度持续攀升。
上周五,中国搜索引擎巨头百度也不甘落后,推出了Ernie 4.5 Turbo和推理优化版Ernie X1 Turbo模型,进一步加剧了市场竞争。
阿里巴巴新推出的Qwen 3将传统AI任务与先进动态推理技术相结合,为应用与软件开发者提供了一个更加灵活高效的平台。相比年初紧急发布的Qwen 2.5-Max,Qwen 3在性能上实现了显著提升。
Qwen 3基于36万亿字节的庞大数据集进行训练,并在后续阶段经历多轮强化学习。它巧妙融合了快速思考与慢速思考模式,在推理、指令遵循、工具利用及多语言能力等方面实现显著提升,为全球开源模型树立了新的性能标杆。
Qwen 3系列涵盖八种模型,包括两个参数分别为300亿和2350亿的混合专家(MoE)模型,以及六个参数从0.6亿至32亿不等的密集模型。每种模型均在其尺寸类别内实现了开源模型中的顶尖性能。
尤为Qwen3的300亿参数MoE模型在效率上实现了十倍提升,仅需激活30亿参数即可媲美上一代Qwen2.5-32B模型的性能。同时,Qwen3的密集模型继续突破极限,以一半参数数量实现高性能。例如,Qwen3的320亿版本在多个层级上超越了Qwen2.5-72B模型的性能。
四月成为大型模型发布的密集期。OpenAI推出了GPT-4.1 o3和o4 mini系列模型,谷歌发布了Gemini 2.5 Flash Preview混合推理模型,而Doubao则宣布了1.5·Deep Thinking模型。行业内其他主要玩家也开源或更新了众多模型。关于DeepSeek R2即将发布的传闻甚嚣尘上,尽管这些报道大多仍属猜测。
无论DeepSeek R2是否发布,Qwen3已抢占先机,成为大型模型“普及化”的真正起点。
作为中国首款混合推理模型,Qwen 3支持两种独特的推理模式:慢速思考模式适合处理复杂问题,通过逐步推理得出最终答案;而快速思考模式则适用于简单问题,能够迅速给出回应。Qwen 3的所有模型均为混合推理模型,这一创新设计将“快速思考”与“慢速思考”融为一体,根据任务需求灵活切换思考模式,显著降低了计算资源消耗。
Qwen 3的API允许用户自定义“思考预算”(即用于深度推理的最大令牌数),从而满足不同场景下AI应用的多样性能和成本需求。例如,40亿参数的模型适合移动设备,80亿参数的模型可顺畅部署于计算机和汽车系统,而320亿参数的模型则备受大型企业青睐。
在衡量数学解题能力的AIME25评估中,Qwen 3以81.5分的优异成绩刷新了开源模型的记录。在评估编码能力的LiveCodeBench测试中,Qwen 3突破70分大关,超越Grok3。在评估与人类偏好一致性的ArenaHard评估中,Qwen 3以95.6分的惊人成绩超越OpenAI-o1和DeepSeek-R1。
尽管性能大幅提升,Qwen 3的部署成本却大幅降低。其全功率版本仅需四台H20 GPU即可部署,内存使用量仅为类似性能模型的三分之一。
Qwen-3模型支持119种语言和方言,目前这些模型已在Apache 2.0许可下开源,并可在Hugging Face、ModelScope和Kaggle等平台上获取。阿里巴巴还推荐使用SGLang和vLLM等框架进行模型部署,同时支持Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具进行本地使用。
Qwen-3还专注于智能代理和大型语言模型的应用。在评估代理能力的BFCL测试中,Qwen-3以70.8分的新高分超越Gemini2.5-Pro和OpenAI-o1等顶级模型,显著降低了代理有效利用工具的门槛。
Qwen-3原生支持MCP协议,具备强大的函数调用能力。结合包含预建工具调用模板和解析器的Qwen-Agent框架,它极大地降低了编码复杂性,使代理能够在手机和计算机上高效运行。
Qwen-3的预训练数据集相比Qwen-2.5显著扩大。Qwen-2.5基于18万亿令牌进行预训练,而Qwen-3则接近翻倍,达到约36万亿令牌。为构建这一庞大数据集,Qwen团队不仅从互联网上收集数据,还从PDF文档中提取信息,并利用Qwen-2.5-VL和Qwen-2.5等模型提高提取内容的质量。
为增加数学和编码数据的数量,Qwen团队利用Qwen-2.5-Math和Qwen-2.5-Coder等专门模型合成数据,包括教科书、问答对和代码片段等多种格式。
预训练过程分为三个阶段。第一阶段(S1)在超过30万亿令牌上进行,上下文长度为4K令牌,为模型奠定了语言技能和基础知识。第二阶段(S2)通过增加STEM、编程和推理任务等知识密集型数据的比例来改进数据集,并额外预训练5万亿令牌。在最终阶段,Qwen团队使用高质量长上下文数据将上下文长度扩展至32K令牌,确保模型能有效处理更长输入。
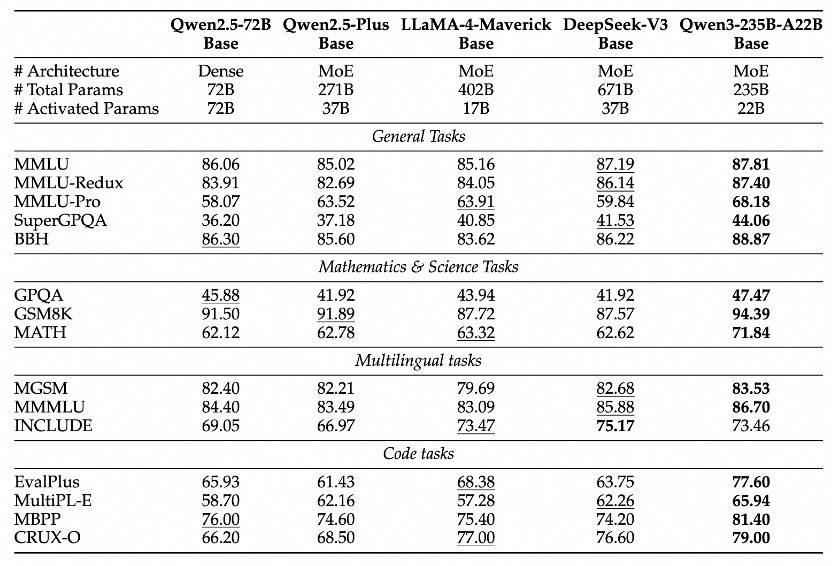
得益于模型架构的改进、训练数据的增加以及训练方法的优化,Qwen3 Dense基础模型的性能可与参数更多的Qwen2.5基础模型相媲美。例如,Qwen3-1.7B/4B/8B/14B/32B-Base的性能与Qwen2.5-3B/7B/14B/32B/72B-Base相当。尤其在STEM、编码和推理等领域,Qwen3 Dense基础模型甚至超越了规模更大的Qwen2.5模型。
至于Qwen3 MoE基础模型,它们在性能上与Qwen2.5 Dense基础模型相当,但激活参数仅占10%,从而显著节省了训练和推理成本。
在后续训练中,为开发兼具推理和快速响应能力的混合模型,Qwen团队实施了四阶段训练过程,包括:长推理链的冷启动、长推理链的强化学习、推理模式的整合以及一般强化学习。