在AI领域,一场关于成本与创新的讨论正在热烈进行,而DeepSeek作为这场讨论中的焦点,其动向备受瞩目。近日,DeepSeek宣布了一个重大决定:自2025年4月1日起,其最新模型将全面免费开放给所有PC端和APP端用户,此前用户仅能免费体验3.5版本。这一消息迅速引发了业界的广泛关注和讨论。
然而,就在DeepSeek宣布免费开放模型的同时,另一则消息也悄然传来。据The Information报道,苹果在寻找AI合作伙伴时,虽与多个国内对象进行了深入交流,并与阿里巴巴取得了重大进展,但最终却拒绝了DeepSeek。这意味着,DeepSeek未能进入苹果的供应链,这一结果无疑令人感到意外和惋惜。
尽管如此,DeepSeek并未因此陷入孤立。相反,它与国内互联网巨头BAT们之间的关系显得颇为微妙。一方面,文小言、腾讯元宝等AI产品接入了DeepSeek大模型,为用户提供更多选择;另一方面,阿里云、腾讯云、华为云等主流云服务平台也上线了DeepSeek大模型,鼓励用户尝试。这种既是对手又是队友的关系,让人不禁对DeepSeek的未来充满期待。
DeepSeek的初衷,是打破AI领域的传统观念,证明“条条大路通罗马”。在生成式AI革命爆发之后,算力成为衡量大模型能力的关键指标之一。然而,算力紧张导致AI成本居高不下,成为行业发展的瓶颈。DeepSeek通过算法优化等手段降低了AI成本,为行业提供了新的思路和方向。这一创新不仅消解了算力壁垒,也符合全球互联网巨头降低成本、推动AI普惠的共同愿望。
DeepSeek的创始人梁文锋表示,他们希望形成一种生态,即业界直接使用DeepSeek的技术和产出,而他们则专注于基础模型和前沿创新。这种错位竞争的策略,或许正是DeepSeek能够在BAT们的包围中脱颖而出的关键。
事实上,BAT们对DeepSeek的态度颇为友好,这背后的原因并不简单。首先,降低AI成本一直是BAT们的共同目标。他们不断推动技术创新,共同推动大模型定价进入“厘时代”。例如,字节跳动设计的UltraMem稀疏模型架构,有效解决了传统主流MoE架构的推理时高额访存问题;百度则点亮了国内首个自研万卡集群,通过集群效能最大化降低单位算力成本。

其次,模型蒸馏成为获取低成本AI的重要路径。李飞飞团队训练的s1人工智能推理模型,就是其中的代表。这一模型以阿里巴巴通义千问为基座模型进行微调,在数学和编码能力测试中表现出色,且耗费极低。模型蒸馏为AI落地提供了更多可能,也指明了新的前进方向。
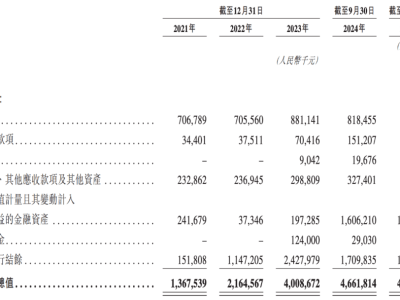
BAT们或许也在考虑与DeepSeek结下善缘。随着DeepSeek规模的不断扩大,资源瓶颈问题日益凸显。尽管DeepSeek背靠的幻方量化拥有千亿元体量,但客户的资金并不等同于可以随意投入的资金。因此,BAT们可以在算力、数据、场景等方面全方位助力DeepSeek,实现双赢。
BAT们一直青睐富有特色的AI初创企业。被誉为“AI六小龙”的智谱AI、月之暗面、百川智能等背后不乏腾讯、小米、美团等巨头的身影。这表明,AI创新是一场马拉松而非短跑,比拼的是耐力与毅力。无论是BAT们这样的头部选手,还是DeepSeek这样的初创企业,都有弯道超车的机会。
在这场AI领域的竞争中,DeepSeek以其独特的创新理念和策略赢得了业界的关注和认可。然而,将其神化也大可不必。毕竟,AI创新之路漫长且充满挑战,需要各方共同努力才能推动行业持续健康发展。