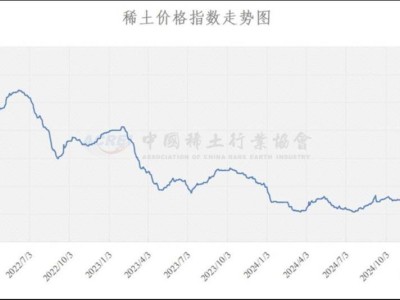
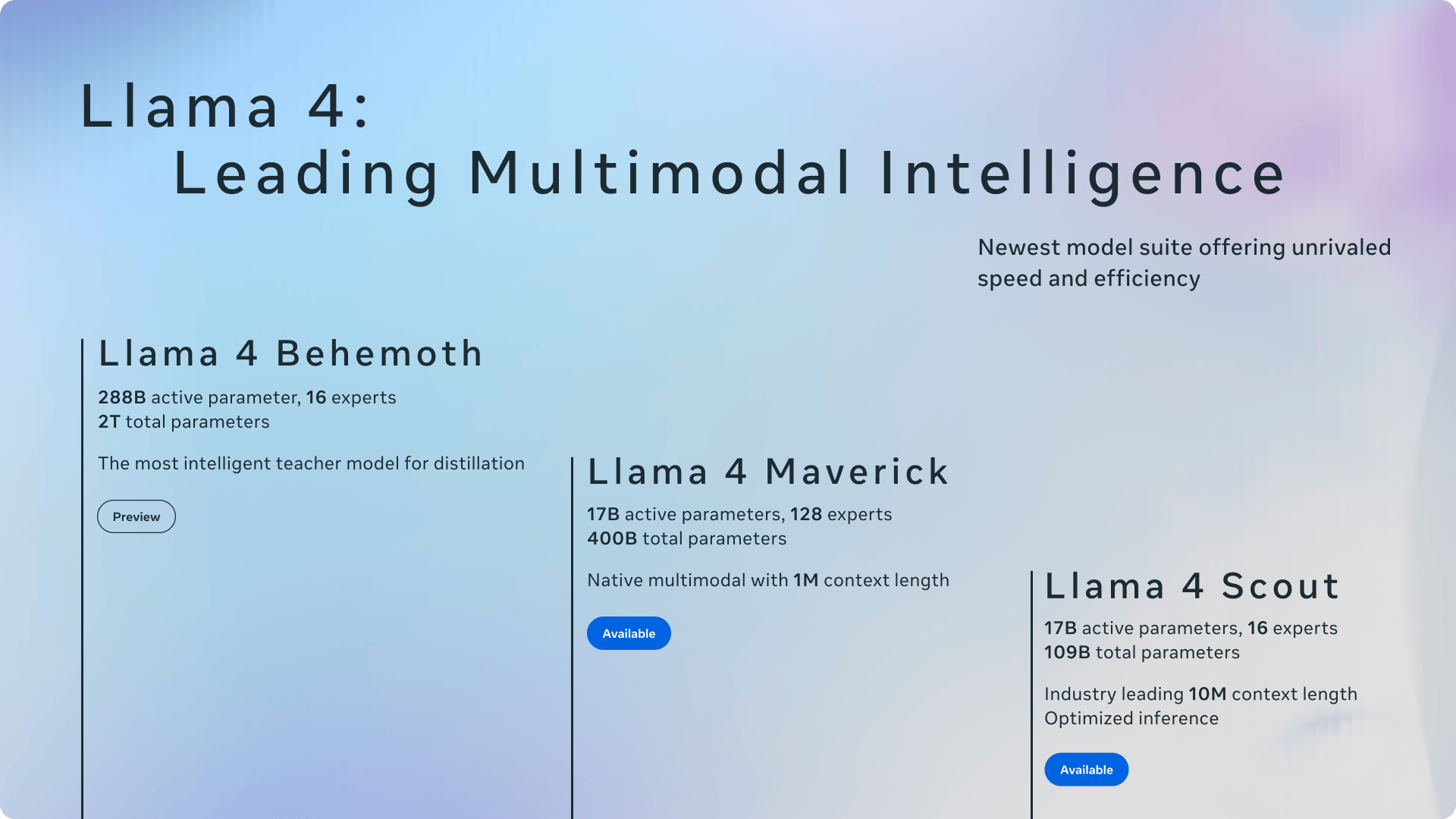
近期,全球开源领域的巨头meta发布了一系列新动向,引发了业界的广泛关注。4月5日,meta正式推出了Llama 4系列中的两款新模型:Scout(侦察者)和Maverick(独行侠),并提前展示了尚在训练阶段的Behemoth(巨兽)模型。然而,这一系列的发布并未如meta所期望的那样顺利,反而因实测效果未达预期而陷入了一场“刷榜”风波。
根据meta的介绍,Llama 4 Maverick在LM Arena评测榜中取得了第二名的佳绩,超越了ChatGPT-4o、DeepSeek-V3等一众领先模型,仅次于谷歌的Gemini 2.5 pro。然而,这一成绩很快便受到了质疑。LM Arena平台在社交媒体上指出,meta在测试中使用的Llama 4 Maverick模型是针对对话优化后的定制版本,而meta在公告中并未明确这一点。LM Arena表示,将添加Maverick的公开版本,并更新排行榜政策,以确保公平性和可重复评估性。
LM Arena是一个由加州大学伯克利分校SkyLab研究人员创建的模型基准测试平台,采用众包投票的方式评选最佳大模型。用户可以向两个匿名的AI对话助手提出任何问题,并投票选出认为更优的答案。在关于Llama 4的回应中,LM Arena提到,初步分析显示,风格和模型回应的语气是影响排名的重要因素,正在进行更深入的分析,表情符号的使用或许也会产生影响。
业内专家指出,尽管LM Arena的众包形式具有泛化性,但仍存在“刷榜”风险。北京理工大学研究语言模型评测与推理方向的博士生袁沛文表示,通过各种隐蔽的方式可以实现去匿名化,大模型厂商就可以通过海量IP来为自己的模型刷票。现有的大模型评测方式都难以做到完全的客观、全面。
面对质疑,meta副总裁兼GenAI负责人Ahmad Al-Dahle在社交媒体上否认了在测试集上进行模型训练的说法,并表示用户感知到的质量差异是由于稳定性还没有完全调整到位。除了备受争议的LM Arena测试外,meta公布的结果显示,Llama 4 Maverick在部分基准测试上表现优于GPT-4o、Gemini 2.0 Flash、DeepSeek-V3等模型,但不及更为领先的GPT-4.5、Claude 3.7 Sonnet、Gemini 2.5 Pro等。
值得注意的是,meta此次发布的Llama 4模型是其首批使用MoE(混合专家)架构的模型。在过去一年多的时间里,meta的研究人员一直在争论是否要将Llama 4变成MoE模型,这一决定对meta来说并不容易。MoE架构在处理单个token时只激活模型中的部分参数,以实现更高的计算效率,DeepSeek-V3、阿里Qwen2.5-Max等模型也是基于这一架构。
自DeepSeek年初引发热议以来,meta在开源领域的领先地位受到了巨大冲击。据报道,meta为此组建了多个专门的研究小组,对DeepSeek进行分析,并希望借此改进Llama模型。尽管面临诸多挑战和质疑,但meta仍在不断探索和创新,以保持其在全球开源领域的竞争力。