在人工智能领域的大模型竞赛迈入第三个年头之际,一家源自中国杭州的初创企业DeepSeek犹如一条活力四射的鲶鱼,为全球大模型生态带来了前所未有的活力与变革。
自蛇年春节以来,中国AI行业掀起了一股竞相接入DeepSeek的热潮。在短短一个多月的时间里,从芯片制造商、云服务提供商、算力服务商、软件企业到面向终端用户的各类硬件厂商,超过百家中国公司已宣布加入DeepSeek的合作伙伴网络,借助其开源模型的能力,为自身的业务发展开辟了新的想象空间。
DeepSeek无疑极大地推动了大模型的普及,但与之俱来的还有一个更为关键的问题——算力。围绕这一核心议题,市场态度经历了多次波动。初期,DeepSeek凭借低算力成本的特点,一度对英伟达等算力厂商造成了股价冲击。随后,随着访问用户的激增和私有化部署需求的增长,算力概念股又强势反弹,供不应求。最近,DeepSeek还公布了其理论成本和利润率,再次在AI圈内引发了广泛讨论。
随着DeepSeek合作伙伴网络的不断扩大,由OpenAI引发的芯片硬件侧的军备竞赛能否持续?这场算力游戏又将带来哪些新的规则?
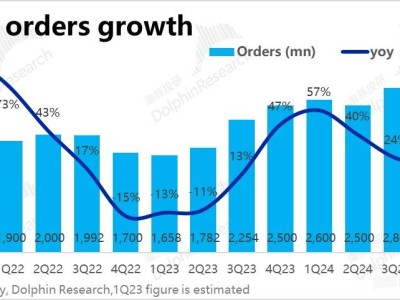
DeepSeek以低成本和高性能著称,根据官方数据,每个H800节点每秒能处理73.7k/14.8k个输入/输出tokens,理论单日总收入可达562027美元,成本利润率高达545%,其“中国式创新”激活了国产算力生态。
在DeepSeek的合作伙伴中,表现最为积极、行动最快的可以分为四类:基础层(包括国产芯片厂商和云服务提供商)、中间层(AI基础设施厂商)以及在B端和C端的软硬件厂商。据不完全统计,第一批接入DeepSeek的企业已接近百家。
“每天都有十几个咨询,从春节复工后就一直没休息过。”一位AI基础设施厂商的商务人员表示。
作为连接大模型底层算力和下游应用的中间层,AI基础设施厂商既是第一批接住DeepSeek“流量”的玩家,也是第一批受益者。例如,硅基流动创始人袁进辉在DeepSeek出圈后,迅速与华为合作,完成了DeepSeek-R1和V3在昇腾生态的适配工作。
与AI基础设施厂商同样敏锐的,还有国产芯片厂商。一位智算中心服务商表示,此轮DeepSeek热潮中,国产AI芯片厂商的反应速度很快,几乎与国际玩家如英伟达同步接入。
紧随其后的是云服务提供商和面向终端的软硬件厂商。云服务提供商方面,几乎所有“互联网云”都在春节期间上线了基于DeepSeek模型的API服务,掀起了一轮新的“低API价格+开源模型”战,云端算力推动了DeepSeek在不同行业的加速渗透。
在硬件方面,手机厂商是最先拥抱DeepSeek的玩家之一。而在用户感受最为直观的软件应用侧,包括腾讯在内的大厂也携“超级应用+DeepSeek”卷入竞争,为大模型竞赛再添一把火。
在分食DeepSeek流量的背后,不同玩家其实各有打算。从算力层来看,拥有充足算力储备的云服务提供商动力更强。它们既是中国算力市场的投资主力,向外大规模投资固定资产,包括采购芯片、服务器、租赁土地建数据中心等,对内也会自研芯片。
以阿里和百度为例,2024年全年,阿里的资本支出总计超过724亿元,百度超过82亿元。据此前报道,阿里、字节跳动也早已完成10万卡级别的算力储备。
DeepSeek通过模型压缩、稀疏计算、混合精度训练等多种技术手段,验证了低算力成本复现高性能模型的可行性,也给自研芯片的大厂带来了“自供血”机会。
“自供血、对外租赁,云服务提供商有自己的业务闭环。”一位行业专家表示。
在战略层面,借助自有云业务,BAT和字节跳动可以通过DeepSeek达成两大目的:一是通过DeepSeek这一超级流量入口,与自身产品协同,短期承接流量;二是有助于鞭策内部团队,在对比中提升自身模型能力。
DeepSeek的出现改变了大众对大模型商业本质的思考。原先,公众认为大模型可能只是一个用于日常对话、应用办公的工具,但事实上,DeepSeek已成为一个超越互联网、甚至超越操作系统的超级流量入口。
据Sensor Tower数据显示,截至某日期,DeepSeek移动端的日活数据已从超过1500万的峰值下滑至700万左右。与此同时,其他大模型如元宝、豆包、通义等均实现了访问量和日活的大幅增长。
DeepSeek的模型能力有目共睹,有流量有市场,且前期在C端以免费模式实现用户数的快速增长,头部大厂自然会迅速跟进。在中国互联网历史上,像DeepSeek这样得到全行业追捧和争抢接入的产品并不多见。
在应用侧,DeepSeek以低成本和低功耗支持复杂AI任务的运行,推动了AI进一步下沉至智能终端、汽车智能驾驶和产业侧。手机厂商如华为、荣耀、OPPO等宣布在AI助手中接入DeepSeek,这有利于它们扩充云端AI生态,并有望拉动手机SoC的需求量。
然而,伴随“接入DeepSeek”浪潮而来的,是服务器繁忙的提示。从用户体验来看,服务器繁忙、延迟加剧等问题日益凸显。即使是AI基础设施厂商也不得不开始限流,寻求更多的算力资源。
那么,这些DeepSeek的合作伙伴们,它们的算力到底够不够?行业目前的共识是短期算力洗牌,长期算力短缺。
“短期算力洗牌”指的是DeepSeek打破了过去模型厂商“大力出奇迹”的叙事,通过模型架构、预训练和推理侧的系统级工程手段,降低了模型部署的算力门槛,短期内给国产芯片、算力服务商等整合国产算力、推动国产算力洗牌提供了机会。
具体来说,一方面,DeepSeek降低了对高性能芯片的依赖,给国产芯片提供了更多机会;另一方面,它解决了部分智算中心算力闲置的困局。一直以来,强劲性能都是英伟达高端GPU的护城河,也是起步较晚的国产芯片的一大软肋。DeepSeek的出现降低了对高性能芯片的依赖,即使是性能较低的GPU也能胜任DeepSeek的本地化部署需求。
而对一些部署国产芯片的智算中心而言,DeepSeek出圈也短期解决了算力闲置和碎片化问题。中国智算中心项目已超过600个,各地也在兴建千卡、万卡算力资源池。然而,在过去,由于缺少一个成本低、性能好且开源的模型,很多算力没有得到有效利用。
但DeepSeek打破了这一窘境。首先,国产芯片厂商反应迅速;其次,作为一个真正“好的开源大模型”,它带动了上下游生态,叠加政策驱动,推动了过去闲置的国产算力真正地用起来。
然而,短期洗牌过后,长期来看,算力还是短缺的。据IDC数据,2024年中国智能算力规模同比增长74.1%,增幅是同期通用算力增幅的3倍以上。未来智能算力内部训练算力占比会下滑,推理算力占比将上升。
推理算力猛涨的背后,是行业对“AI加速渗透千行百业”的期待。以目前日活量、日均token调用量为基础进行估算,10亿级别DAU的应用接入DeepSeek且全面普及使用后,所需的推理算力规模巨大。
事实上,中国科技大厂已经进入新一轮的扩张周期。以阿里为例,近两年其资本支出呈现出高增趋势,部分季度甚至呈现三位数高增。阿里管理层在最新财报电话会中给出的指引是,未来三年在云和AI的基础设施投入将超越过去十年的总和。
比起讨论“是不是泡沫”,国产算力现阶段还有更需要做的事。行业需要更多的高性价比算力,支持像DeepSeek这样有价值的国产自主创新,并积极复现其技术路线,以及在具体业务场景中寻找更具性价比的算力方案。