全球科技界近日因DeepSeek的崛起而沸腾。在直播中,马斯克携手其所谓的“地球上最聪明的AI”——Gork 3亮相,他声称该AI的推理能力超越了所有已知模型,并在推理-测试时间得分上优于DeepSeek R1和OpenAI o1。这一消息紧接着微信宣布接入DeepSeek R1进行灰度测试,被视为AI搜索领域即将迎来巨变的前兆。
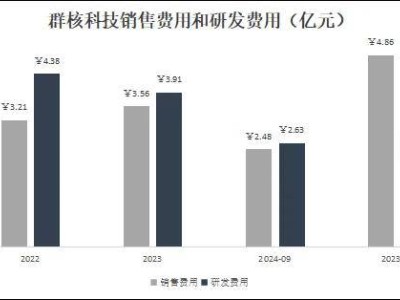
目前,微软、英伟达、华为云、腾讯云等众多全球科技巨头已纷纷接入DeepSeek。网友们更是脑洞大开,开发出算命、预测彩票等新奇应用,其热度直接转化为经济效益,推动DeepSeek的估值飙升,最高已达到千亿美金。DeepSeek之所以备受瞩目,除了其免费且易用的特点外,还因为它仅以557.6万美元的GPU成本就训练出了与OpenAI o1实力相当的DeepSeek R1模型。相比之下,过去几年的“百模大战”中,国内外AI大模型公司动辄投入几十亿甚至上百亿美元。
然而,Gork 3成为“全球最聪明AI”的代价同样不菲,马斯克透露Gork 3的训练累计消耗了20万块英伟达GPU(每块成本约3万美元),而据业内人士估计,DeepSeek的训练成本所用的GPU数量仅在1万多张。尽管如此,从50美元到上百亿美元的训练成本差异,仍引发了广泛讨论:DeepSeek的能力究竟有多强?训练一个大模型需要多少钱?涉及哪些环节?
业内人士指出,在解答这些问题前,需要先澄清一些误解。首先,DeepSeek并非只有一个模型,而是包含多个大模型,每个模型的功能各不相同。557.6万美元只是其通用大模型DeepSeek-V3训练过程中的GPU花费,即净算力成本。通用大模型与推理大模型DeepSeek-R1的主要区别在于技术实现和应用场景:通用大模型接收明确指令,基于概率预测快速回答;而推理大模型则接收简单任务,基于链式思维逐步推理得出答案。
其次,尽管推理大模型是前沿技术,但并不意味着它比通用大模型更高级或更好用。大模型领域专家刘聪指出,对于某些问题,如询问某个国家的首都,推理大模型可能不如通用大模型高效且准确,甚至会出现过度思考导致错误答案的情况。因此,他建议在进行数学难题、挑战性编码等复杂任务时使用推理模型,而在总结、翻译、基础问答等简单任务中,通用模型更为适用。
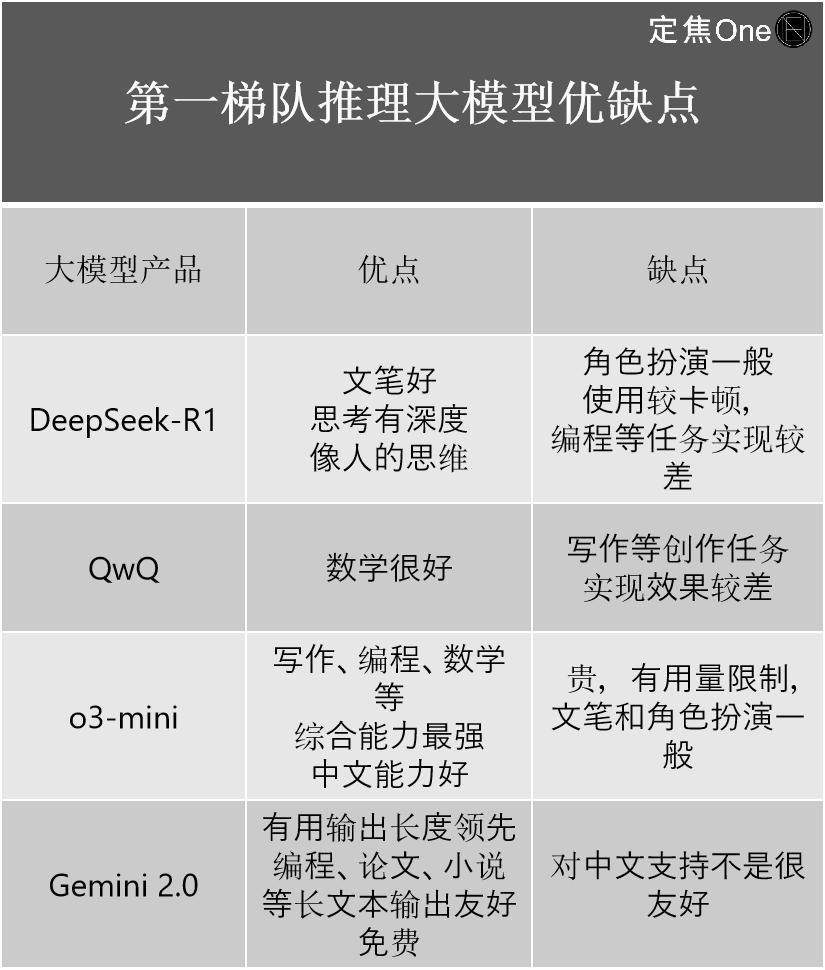
在评估DeepSeek的真正实力时,综合权威榜单和专家意见,DeepSeek在推理大模型和通用大模型领域均位列前茅。推理大模型第一梯队包括OpenAI的o系列、Google的Gemini 2.0、DeepSeek-R1以及阿里的QwQ。尽管DeepSeek-R1被视为国内顶尖模型,但与OpenAI最新的o3相比仍有一定差距。然而,它的出现大大缩小了国内外顶尖水平之间的差距,从之前的2-3代差距缩小到了0.5代。
在通用大模型领域,第一梯队包括Google的Gemini(闭源)、OpenAI的ChatGPT、Anthropic的Claude以及DeepSeek和阿里的Qwen。尽管DeepSeek-R1震惊了全球科技圈,但每家大模型产品都有其自身的优势和局限性。例如,刘聪发现DeepSeek最新发布的多模态大模型Janus-Pro在图像理解和生成任务上的表现并不理想。
关于训练大模型的成本问题,刘聪表示大模型的诞生主要分为预训练和后训练两个阶段。预训练涉及大量文本语料的输入,使模型完成知识摄取;后训练则包括模型微调(SFT)和强化学习(RLHF),使模型学会如何运用所学知识。无论是通用大模型还是推理大模型,国内外遵循的都是这一流程。然而,各家大模型的训练成本差异巨大,主要集中在硬件、数据和人工三个方面。
硬件方面,是购买还是租赁GPU会直接影响成本。购买前期投入大但后期成本低,而租赁则持续产生费用。数据方面,是购买现成数据还是自行爬取数据,也会影响成本。每次训练的成本、中间迭代的版本数量以及是否存在算力浪费现象等因素,都使得最终成本难以准确预估。尽管外界曾按照GPU估算顶尖模型的训练成本,但由于闭源和算力浪费等因素,实际成本难以知晓。直到DeepSeek以557.6万美元的成本出现。
然而,需要注意的是,557.6万美元只是DeepSeek技术报告中提到的基座模型DeepSeek-V3的训练成本,并不包括前期研究、架构及算法的试错等成本。而且,DeepSeek-R1的具体训练成本在论文中并未提及。半导体市场分析和预测公司SemiAnalysis指出,考虑到服务器资本支出、运营成本等因素,DeepSeek的总成本在4年内可能达到25.73亿美元。尽管如此,与其他大模型公司相比,DeepSeek的成本仍然较低。
DeepSeek不仅在模型训练阶段效率更高,在调用推理阶段也更高效、成本更低。从DeepSeek给出的各大模型API定价可以看出,其成本远低于“OpenAI们”。DeepSeek-R1的API定价为每百万输入tokens 1元(缓存命中),每百万输出tokens 16元;而OpenAI的o3-mini的定价分别为0.55美元(4元人民币)和4.4美元(31元人民币)。低价策略使得中小企业更容易接入DeepSeek。
DeepSeek之所以能够实现低成本高效益,关键在于从模型结构到预训练和后训练的全面优化。例如,在模型结构上,DeepSeek采用了细粒度专家分割和共享专家隔离技术,提高了MoE参数效率和性能;在数据处理上,使用了FP8低精度训练来加速深度学习训练;在后训练中的强化学习上,选择了GRPO算法来降低算力要求;在推理层面上,用多头潜在注意力机制(MLA)替代了传统的多头注意力(MHA),显著降低了显存占用和计算复杂度。
DeepSeek的降本不仅给从业者带来了技术上的启发,也影响了AI公司的发展路径。英诺天使基金合伙人王晟指出,AI产业在跑通AGI方向上通常有两种路径选择:一种是“算力军备”范式,另一种是“算法效率”范式。DeepSeek的一系列模型证明了在天花板涨不动的情况下,将重点放在优化效率而非能力增长上的范式具有可行性。