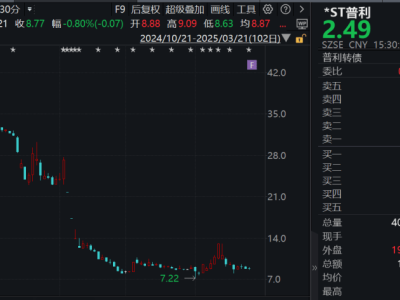
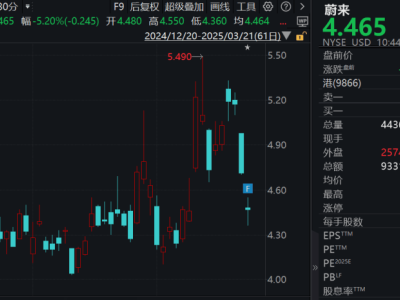
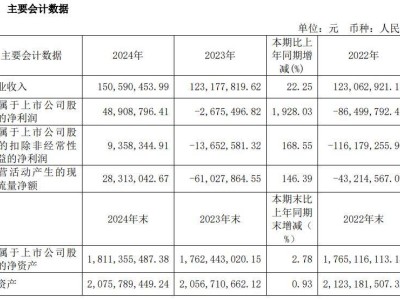
在人工智能的广阔天地里,技术创新始终是驱动行业前行的核心动力。近期,一个名为DeepSeek的团队凭借其最新研发的DeepSeek-v3大模型,在AI界掀起了滔天巨浪。该模型以惊人的效率——仅需Llama3十一分之一的算力,便实现了性能上的超越,这一成就无疑让整个科技圈为之震动。而这一切的背后,是一群来自清华、北大等高等学府的年轻精英们的智慧结晶。
DeepSeek-v3之所以能够脱颖而出,关键在于其背后的多项技术革新。团队创造性地提出了MLA(Multi-head Latent Attention)新型注意力机制,这一机制极大地削减了计算负担和推理过程中的显存占用。在此基础上,他们更进一步,研发出GRPO(Group Relative Policy Optimization)强化学习对齐算法,这一算法的优化标志着团队在机器学习领域的又一重大突破。

在DeepSeek的团队构成中,年轻人的活力与创造力尤为引人注目。团队中不仅有刚走出校门的应届毕业生,更有如北大计算机学院在读研究生朱琪豪这样的青年才俊。朱琪豪作为DeepSeek-Coder-V1的主导开发者,其研究聚焦于深度代码学习,并已有多篇高质量学术论文发表,展现了团队在人才培养和科研创新上的强大实力。
DeepSeek的创新成果并未止步于理论层面,其在实际应用中的表现同样令人瞩目。以DeepSeek-Math模型为例,它在多个领域展现出了卓越的性能,为用户带来了前所未有的体验提升。无论是学术研究还是商业应用,DeepSeek都能凭借其高效的算法架构迅速响应,提供精准可靠的解决方案。对于广大用户而言,这意味着在解决复杂数学问题、文本生成以及编程辅助等多个场景下,都能享受到DeepSeek带来的便捷与高效。
DeepSeek团队的成功,离不开其独特的团队文化和用人理念。创始人梁文锋自团队创立之初便强调,要以能力而非经验作为吸纳人才的标准。这一理念使得团队中充满了年轻且充满活力的面孔,他们敢于挑战前沿科技,不断寻求技术和科研上的突破。团队还高度重视软硬件的结合,成员背景多元,涵盖了深度学习算法、硬件设计及计算架构等多个领域。这种跨学科的协作模式,为DeepSeek-v3性能的大幅提升奠定了坚实基础。
随着DeepSeek在AI领域的崭露头角,其影响力和潜力也愈发受到行业的认可。特别是“雷军开千万年薪挖DeepSeek研究员”的传闻在业界流传开来后,更是让这个年轻团队成为了众人瞩目的焦点。DeepSeek的故事不仅激发了科技圈的热议,也让更多普通人对这个在科技浪潮中勇立潮头的团队充满了好奇与期待。可以预见的是,在未来的AI发展中,DeepSeek将继续发挥其创新优势,在更多领域发挥重要作用,推动整个大模型产业的进步与变革。