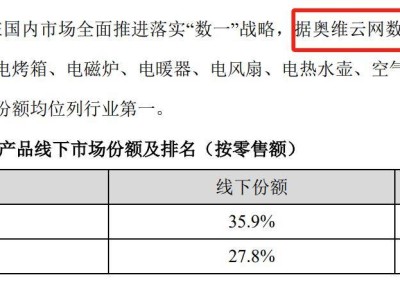
在AI大模型领域,一场技术竞赛正悄然上演。传闻已久的Qwen 3模型,终于在4月29日凌晨揭开神秘面纱,其声称在技术性能上全面超越了备受瞩目的DeepSeek R1。
据业内消息人士透露,杭州一家中型科技公司的算法专家表示,近期网络上关于DeepSeek R2的泄露信息层出不穷,据传R2将于5月发布。Qwen 3选择此时发布,显然意在抢占市场先机。
与此同时,在一家国产大模型开放平台工作的刘露透露,他们团队在Qwen 3发布前不到12小时才得知消息,并立即投入工作,连夜完成了Qwen 3系列模型在该平台的部署上线。这一速度彰显了业界对Qwen 3的高度关注与期待。
Qwen 3的亮相,无疑标志着开源AI大模型技术能力的又一次飞跃。对于产业链下游的应用开发者而言,这意味着一次全新的生态选择机会已经到来。据观察,Qwen 3发布仅10小时后,已有开发者推出了基于Qwen 3系列模型的ChatBot类产品。
Qwen 3系列模型的创新之处在于其支持两种运行模式:思考模式与非思考模式。在思考模式下,模型会进行逐步推理,适用于需要深入思考的复杂问题;而在非思考模式中,模型则提供快速响应,适用于对速度要求高于深度的简单问题。这一设计打破了DeepSeek R1等模型单一慢思考的局限,为用户提供了更灵活的选择。
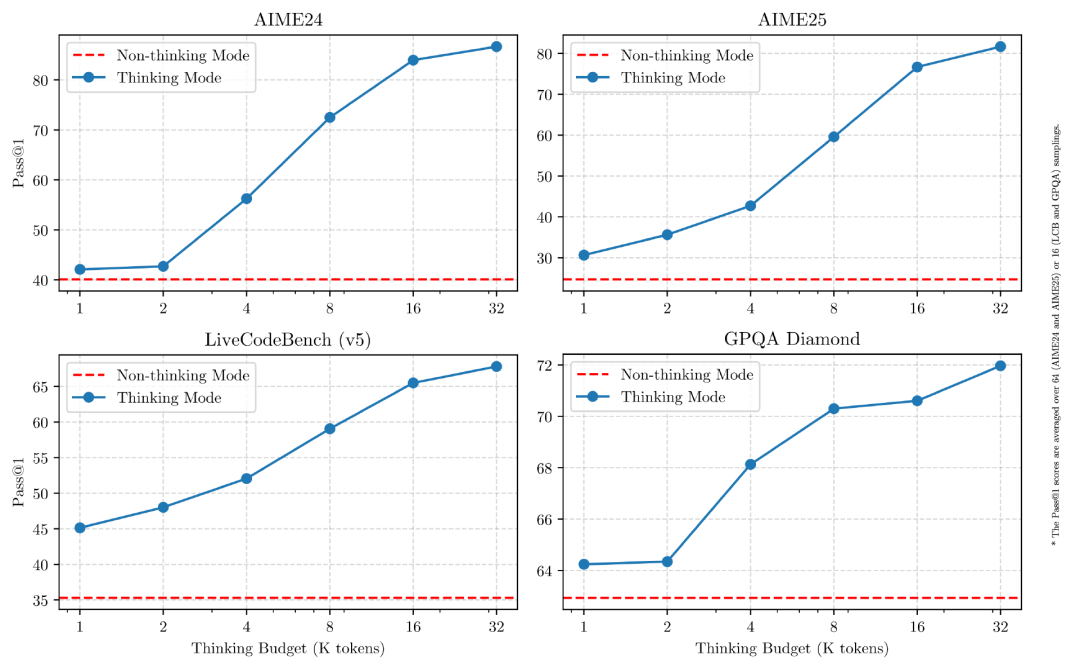
作为国内首个混合推理模型,Qwen 3在性能及成本优化方面也表现出色。本次开源的两个MoE(混合专家)模型——Qwen3-235B-A22B和Qwen3-30B-A3B,在参数规模和激活参数上均有所突破。Qwen3-235B-A22B拥有超过2350亿总参数和220多亿激活参数,而Qwen3-30B-A3B则拥有约300亿总参数和30亿激活参数。这些模型在解决任务时能够高效调动相应模块,节省计算成本。
在性能对比中,Qwen3旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中均展现出优势,超越了DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型。小型MoE模型Qwen3-30B-A3B同样表现优异,与DeepSeek V3、GPT 4o、谷歌Gemma3-27B-1T等模型相比毫不逊色。Qwen3还开源了六个适用于通用任务的Dense模型。
Qwen3的发布,距离DeepSeek R1亮相已过去三个多月。在此期间,尽管包括科大讯飞星火X1、百度文心X1、OpenAI o3 mini等在内的多家厂商纷纷推出推理模型,但均未能真正撼动DeepSeek R1的地位。直到Qwen3的出现,这一格局才有望被打破。
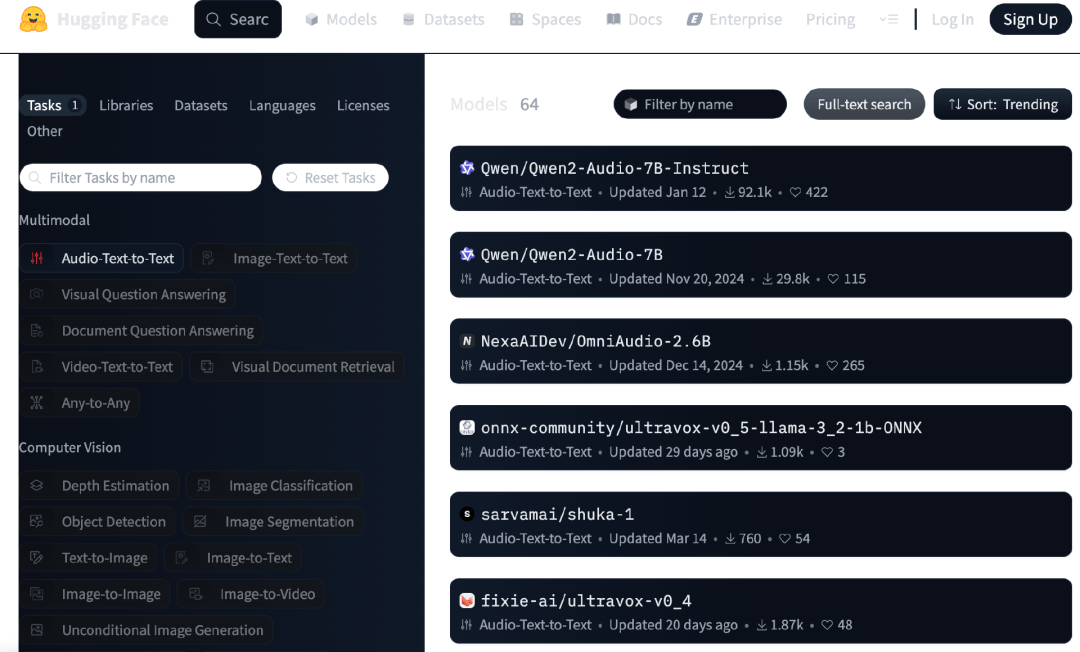
在生态活跃度方面,Qwen系列模型同样表现出色。据全球最大AI开源社区Huggingface的数据显示,Qwen的两款模型在audio-text-to-text任务类目下热度居前。同时,基于Qwen系列的衍生模型数量已超过9万个,成为全球最大的AI模型家族之一。这一成就不仅超越了美国Llama系列,也彰显了Qwen在开源生态中的领先地位。
然而,尽管Qwen3在性能、成本和生态方面均取得了显著成就,但竞争远未结束。DeepSeek R2的即将亮相将为市场增添新的变数。在开源市场“第一通吃”的定律下,谁能成为最终的赢家仍充满未知。无论是DeepSeek、Qwen还是Llama,都需要持续努力以保持竞争力。
值得欣慰的是,在当前这场技术竞赛中,国产玩家Qwen3暂时领跑。这一成就不仅体现了中国AI技术的快速进步,也为全球开源AI大模型的发展注入了新的活力。