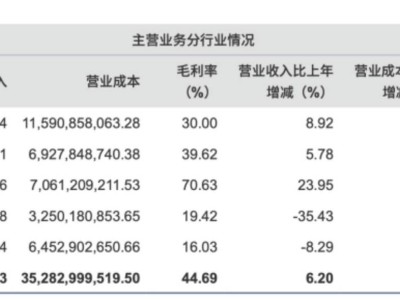
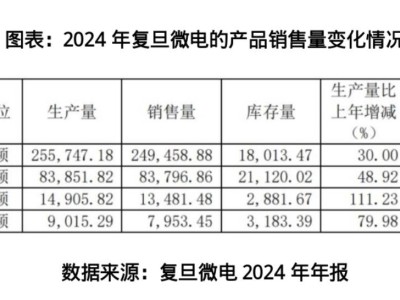
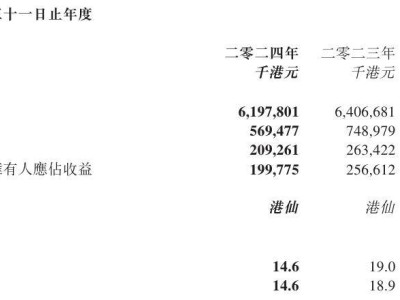
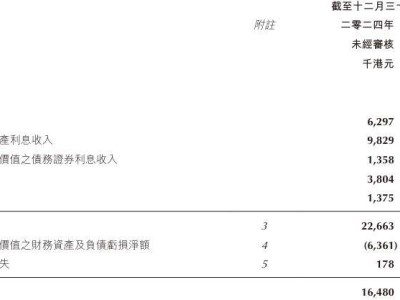
近日,OpenAI在其人工智能技术中迈出了重要的一步,更新了ChatGPT的文生图功能,这一变动标志着AI图像生成领域的一次小幅度革新。以往,ChatGPT依赖DALL-E模型来完成图像生成任务,但此次更新后,这一功能被直接整合进了ChatGPT本身。
新升级后的ChatGPT在图像生成上表现出了更高的准确性。所谓准确性,即指其生成的图像更加贴近用户的实际需求。例如,当用户要求生成一张戴眼镜的猫咪图片时,ChatGPT会先进行分析,然后输出一张细节丰富的、符合要求的图片。ChatGPT还增加了图像修改功能,用户可以根据需要对生成的图像进行调整,直至满意。
在OpenAI的官方直播活动中,研究人员展示了ChatGPT在图像生成方面的几个实例。其中,一张普通的研究人员与奥特曼的合影被ChatGPT轻松转换为动画风格的画作。另一个示例中,ChatGPT成功地在生成的图像上添加了指定的文字,如“Feel The AGI”。
为了亲自体验这一新功能,作者在朋友聚会后进行了尝试。作者通过设定一个详细的提示词,要求ChatGPT和另一款名为即梦AI的图像生成软件分别生成一张赛博朋克风格的城市图片。结果显示,两款软件生成的图片都捕捉到了赛博朋克的精髓,但在细节上各有千秋。不过,从图像清晰度的可控性来看,GPT略逊一筹。即梦AI提供了便捷的细节修复和超清功能,能够显著提升图像的清晰度,而GPT在多次尝试后仍未达到作者的预期。
尽管在清晰度控制上有所欠缺,但ChatGPT在其他方面展现出了其独特的优势。例如,在调整图片尺寸时,ChatGPT会提供多个解决方案,并询问用户更倾向于哪一种。这种互动性为用户提供了更多的选择空间。
ChatGPT还新增了世界知识功能,这一功能使得AI在生成图片时能够更好地理解并应用现实世界的知识,从而生成更加符合逻辑和实际情况的图片。例如,在绘制雪山时,ChatGPT不会错误地添加热带植物;在描绘古代场景时,也不会出现现代科技产品。
为了测试这一新功能,作者设定了一个提示词,要求ChatGPT生成一张通过两个站在滑板上的人推对方的动作来解释牛顿第三定律的图片。结果显示,ChatGPT能够准确地展示两个人在滑板上互相推开的关系,并添加了箭头和英文解释来增强直观性。然而,作者认为这一功能在某种程度上类似于一个图像PPT功能,缺乏一些创新性和深度。
在后续的测试中,作者还分别生成了人的头部骨骼和身体骨骼图片。尽管这些图片在质量上并不算顶尖,但已经能够满足大部分基本需求。与此同时,国内的一些AI图像生成模型如字节、腾讯的文生图模型也具备了类似的功能。
OpenAI的首席执行官Sam Altman对这次更新表示了高度赞赏,认为ChatGPT生成的图片质量令人难以置信,并期待用户能够利用这一功能创作出更多富有创意的内容。同时,他也强调了OpenAI在平衡创作自由和控制权方面的努力,以确保AI的发展符合社会的期望和道德标准。
然而,作者认为,与ChatGPT目前的生成能力相比,更值得关注的是其为何要替代DALL-E模型。作为OpenAI在2021年发布的模型,DALL-E本应持续迭代以变得更加强大。然而,事实上,DALL-E模型的核心架构是自回归模型,这种模型在生成图像时存在速度慢和难以调整的问题。因此,OpenAI选择采用非自回归模型来替代它。
非自回归模型的工作方式是先理解整个图像的结构和细节,然后一次性生成整个图像。这种模型具有更高的效率和更强的整体表现,特别是在处理复杂场景时能够更自然地处理多个物体之间的关系和光影效果。非自回归模型还具有更强的灵活性和可扩展性,能够融合到多模态中生成更多样化的内容。
值得注意的是,非自回归模型并非OpenAI的独创。早在2018年的ICLR会议上就有人提出了这一概念,并最初应用于神经机器翻译领域。近年来,国内的一些企业如阿里巴巴、科大讯飞等也已经引入了这一技术。因此,OpenAI此次的更新可能是看到了国内在这一领域的成熟应用并开始反思和调整自己的策略。