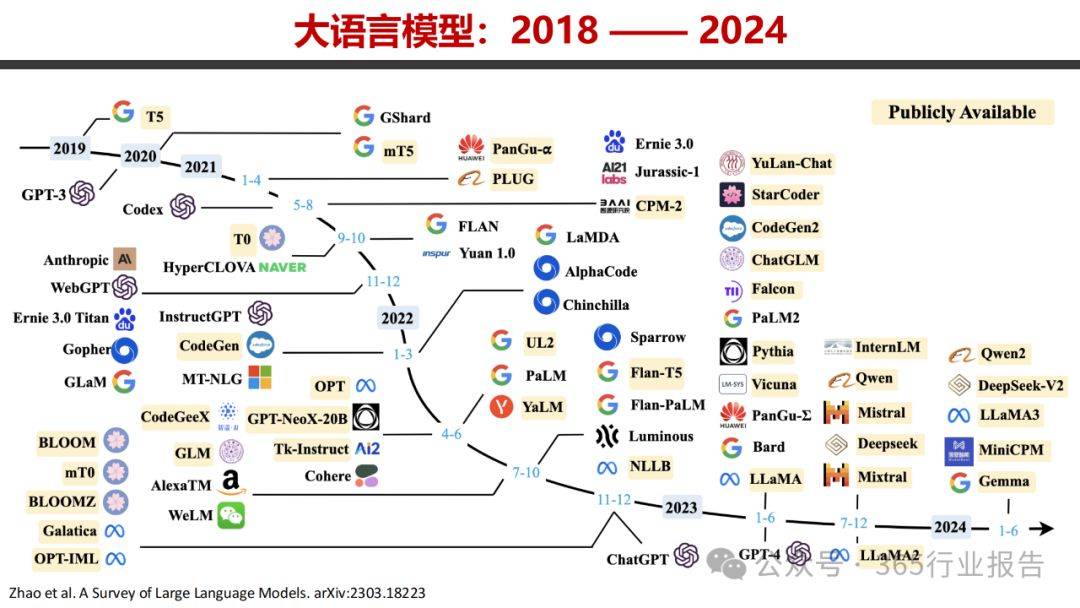
在人工智能的浩瀚星空中,一颗名为DeepSeek的新星正冉冉升起,其光芒源自中国天津大学自然语言处理实验室的卓越创新。DeepSeek项目,自2023年末首次亮相以来,便以惊人的速度迭代升级,引领着大语言模型领域的新一轮变革。
DeepSeek的旅程始于2023年11月,首个版本的问世标志着团队对技术前沿的勇敢探索。随后,2024年5月,DeepSeek V2携带着Mixture of Experts(MoE)的稀疏激活架构及Memory-efficient Low-rank Attention(MLA)技术惊艳登场,这些创新不仅优化了计算效率,更为模型的性能提升铺设了坚实的基石。

时间轴继续向前推进,2024年11月,DeepSeek R1-Lite轻装上阵,而同年12月,DeepSeek V3则以更加高效的训练算法和Multi-Token Prediction(MTP)技术,再次刷新了业界对大模型训练效率的认知。2025年1月,DeepSeek R1的正式发布,更是将强化学习应用于推理模型,开创了推理与对齐一体化的新纪元。
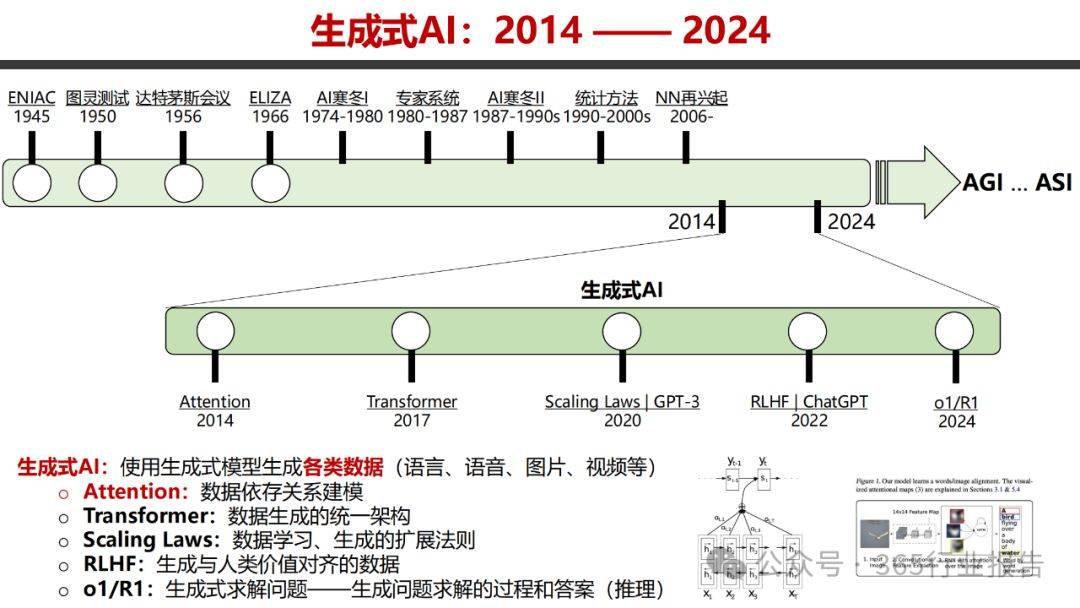
DeepSeek的技术创新不仅体现在模型架构的突破,更在于其对训练与推理过程的深度优化。V3版本通过减少流水线气泡、优化节点间通信、采用FP8训练等技术,显著提升了训练效率。而R1版本则通过独特的强化学习训练框架,实现了推理能力的飞跃,这一成就不仅彰显了团队的技术实力,更为全球AI研究提供了新的视角。
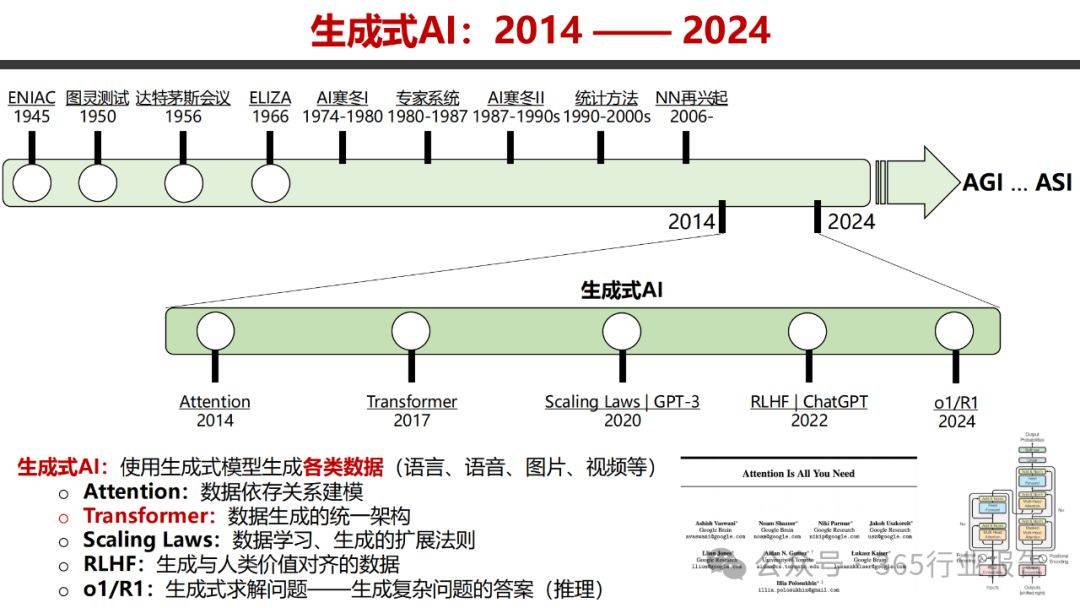
DeepSeek的影响力远不止于此。其高效的训练方式大幅降低了大模型的研发和部署成本,使得更多机构能够涉足这一领域。同时,R1版本的开源发布,更是打破了技术壁垒,为全球研究者提供了宝贵的学习资源,推动了AI技术的健康发展。这一举措不仅彰显了中国在AI领域的创新能力,更颠覆了外界对中国AI水平的传统认知。
DeepSeek的成功背后,是一群顶尖人才的智慧结晶。他们不仅具备深厚的技术功底,更拥有前瞻性的战略眼光。正是这样的团队,才能够在激烈的市场竞争中脱颖而出,推动大模型技术的不断前行。DeepSeek的故事,不仅是一段技术创新的历史,更是一份关于勇气、智慧和坚持的传奇。