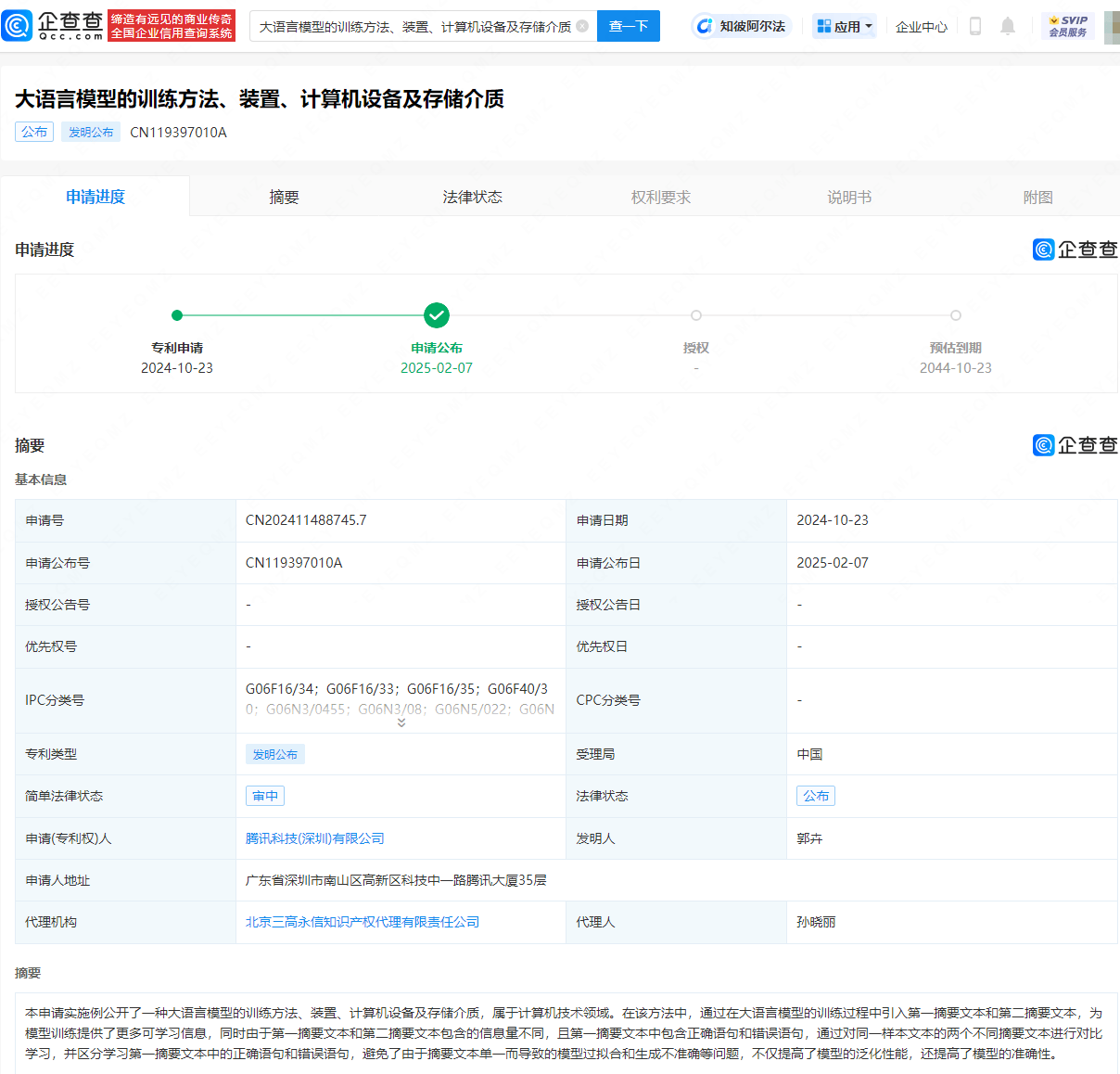
据企查查APP最新披露,腾讯科技(深圳)有限公司近期公布了一项关于“大语言模型训练方法、装置、计算机设备及存储介质”的专利申请。
该专利的核心在于,其在大语言模型的训练流程中创新性地引入了第一摘要文本与第二摘要文本的概念。这一做法为模型提供了更为丰富的学习素材,有效增强了模型的训练效果。值得注意的是,这两类摘要文本在信息量上存在差异,且第一摘要文本内嵌有正确与错误的语句。通过对比学习同一原文的两个不同摘要版本,并精准区分第一摘要中的正确与错误部分,该训练方法有效规避了因摘要文本单一可能引发的模型过拟合及生成内容不准确等问题。
这一创新策略不仅显著提升了大语言模型的泛化能力,即在面对未见过的数据时也能做出准确预测的能力,还进一步增强了模型的准确性,确保了输出内容的可靠性。
此次腾讯科技在大语言模型训练技术上的突破,无疑为人工智能领域的发展注入了新的活力,也展现了该公司在技术创新上的持续探索与追求。