近日,一家仅有7人团队的初创企业Triplegangers遭遇了意想不到的困境,其公司网站突然崩溃,无法正常访问。紧急排查后,CEO和员工们惊讶地发现,导致这一问题的竟是OpenAI的GPTBot爬虫。
GPTBot,作为OpenAI早年推出的一款工具,旨在自动抓取互联网上的数据。然而,Triplegangers的网站却成为了这款工具的“攻击”目标。CEO透露,他们的网站拥有超过65000种产品,每种产品都有一个页面,且每个页面至少包含三张图片。OpenAI的GPTBot在短时间内发送了大量服务器请求,试图下载所有内容,包括数十万张照片及其详细描述。
经过深入分析上周的服务器日志,Triplegangers团队发现,OpenAI使用了超过600个IP地址进行数据抓取。这一行为不仅导致了网站的宕机,还引发了大量的CPU使用和数据下载活动,使得网站在AWS云计算服务上的资源消耗剧增,从而大幅增加了运营成本。
Triplegangers的CEO无奈表示,这基本上就是一场DDoS攻击。尽管Triplegangers的网站上有明确的服务条款,禁止未经许可的AI抓取图片,但显然这并没有起到任何作用。更重要的是,Triplegangers没有正确配置Robot.txt文件,这是告诉搜索引擎网站在索引网络时不要爬取哪些内容的关键文件。
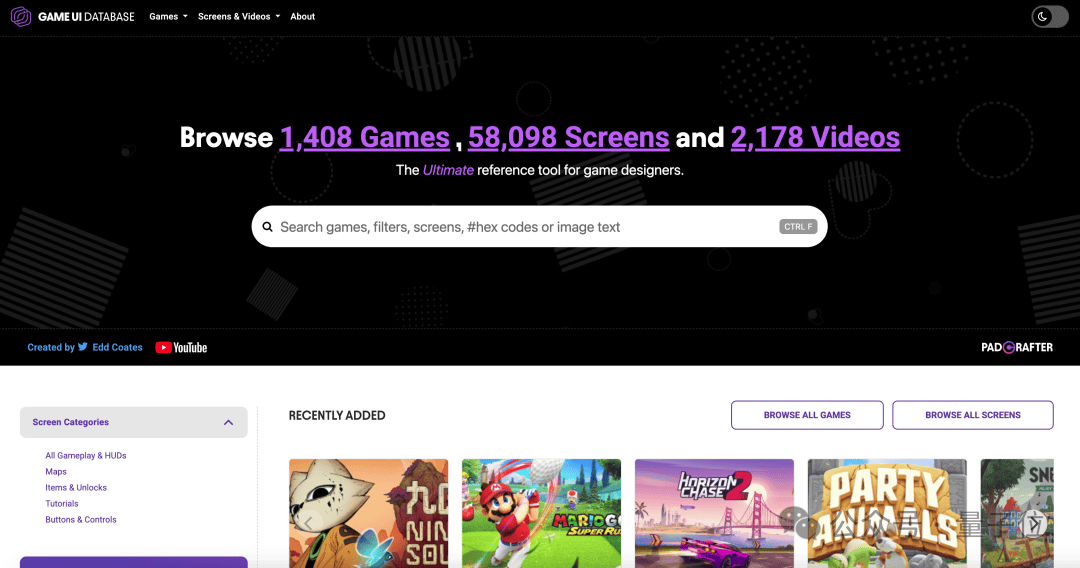
Triplegangers的遭遇并非个例。此前,另一家公司Game UI Database也遭遇了类似的困境。其网站因OpenAI的爬虫行为而几乎瘫痪,每秒被查询2次,导致网站加载速度变慢,用户频繁遭遇502错误。数字产品工作室Planetary的创始人也曾表示,他们为客户重新设计的网站上线后,因Anthropic的爬虫行为导致客户云成本翻倍。
据了解,Triplegangers的7名成员花费了十多年的时间,打造了号称最大“人类数字孪生”的数据库。该网站包含从实际人类模型扫描的3D图像文件,且照片带有详细的标签,涵盖种族、年龄、纹身与疤痕、各种体型等信息。这对于需要数字化再现真实人类特征的3D艺术家、游戏制作者等具有重要价值。
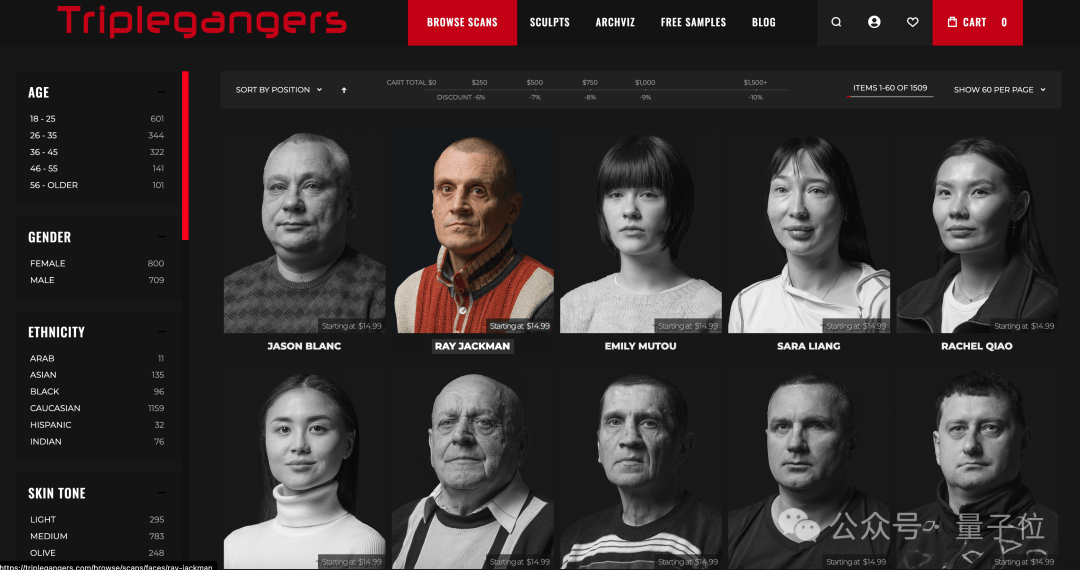
然而,尽管Triplegangers的数据质量极高,但他们却没有正确配置Robot.txt文件来阻止OpenAI的GPTBot爬虫。CEO表示,如果一个网站没有正确配置Robot.txt文件,那么OpenAI和其他公司会认为他们可以随心所欲地抓取内容。这不是一个可选的系统,而是一个必须面对的现实。
截至本周三,Triplegangers已经按照要求配置了正确的Robot.txt文件,并设置了Cloudflare账户来阻止其他AI爬虫。然而,CEO仍然有一个悬而未决的困惑——不知道OpenAI已经从他们的网站中爬取了哪些数据,也联系不上OpenAI。他深表担忧地表示,如果不是GPTBot“贪婪”到让他们的网站宕机,他们可能还不知道它一直在爬取他们的数据。
来自数字广告公司DoubleVerify的一份新研究显示,AI爬虫在2024年导致“一般无效流量”增加了86%。AI公司,尤其是大模型公司,之所以如此疯狂地“吸食”网络上的数据,是因为他们太缺用来训练的高质量数据了。有研究估计,到2032年全球可用的AI训练数据可能就会耗尽,因此AI公司加快了数据收集的速度。

Triplegangers的遭遇引发了网友们的广泛讨论。有人认为GPTBot的做法并不是抓取,更像是“偷窃”的委婉说法。也有网友表示,自从阻止了大公司的批量AI爬虫后,省下了一大笔钱。这一事件再次提醒了在线企业,要想防止大公司未经允许爬虫,必须主动、积极地去查找问题并采取相应的措施。