近期,一场关于人工智能(AI)模型核心理论起源的争论引发了广泛关注。据南华早报的报道,有声音指出,中国科技巨头百度可能在大规模AI模型的关键理论上领先于OpenAI。
在AI大模型的发展历程中,“扩展定律”占据着举足轻重的地位。该定律认为,通过增加训练数据和模型参数,可以显著提升模型的智能能力。这一理论普遍被认为是OpenAI在2020年发表的《神经语言模型的扩展定律》论文中首次提出的,该论文奠定了AI研究的重要基础。
然而,美国虽然通常被视为AI技术的领头羊,但有专家提出,中国可能更早地对这些概念进行了探索。OpenAI的研究表明,模型的性能提升与参数、训练数据和计算资源的增加之间存在幂律关系。这一发现对后续的大规模AI模型开发起到了重要指导作用。
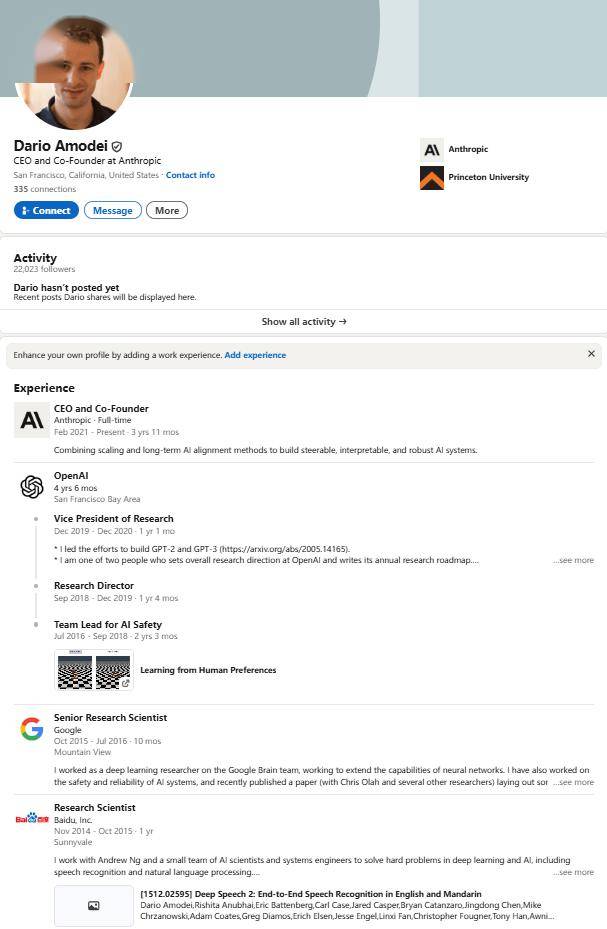
令人意外的是,OpenAI论文的共同作者之一、前OpenAI研究副总裁及Anthropic CEO达里奥·阿莫代伊在一次播客中透露,他在百度工作期间,早在2014年就观察到了类似的现象。根据LinkedIn上的公开信息,阿莫代伊曾在百度担任研究科学家,后转战谷歌和OpenAI。

meta研究员、康奈尔大学博士生杰克·莫里斯也在X(前Twitter)上发文支持这一观点。他指出,扩展定律的初步研究实际上是在百度的2017年,而非OpenAI的2020年。百度硅谷AI实验室在2017年发表了一篇名为《深度学习扩展是可预测的,实证的》的论文,深入探讨了机器翻译和语言建模等领域的扩展现象。
针对这一争论,清华大学计算机科学与技术系副教授刘志远表示,百度和OpenAI的研究是并行发展的,两者都具有重要意义。他强调,扩展定律是支撑涌现智能的基础性原则,在自然、社会和人工系统中广泛存在。百度的工作主要集中在深度学习阶段,而OpenAI则聚焦于大模型阶段。
刘志远还提到,中国在大模型研究方面的实力日益增强,但仍面临计算资源瓶颈等挑战。为了弥补与国际领先者如OpenAI之间的差距,中国需要集中力量发展国产AI芯片,并培养顶尖人才和科研团队,推动原创创新。
近年来,中国在大模型领域的成就逐渐获得国际认可。在第二届人工智能数学奥林匹克竞赛中,阿里巴巴云计算推出的QwQ-32B推理模型表现优异,得到了著名数学家陶哲轩的赞扬。在2024年百度世界大会上,百度宣布了一项新技术,旨在减少图像生成中的“幻觉”问题,并透露其文心(Ernie)基础模型在11月的日常API调用量已达到15亿次,相比去年增长了30倍。