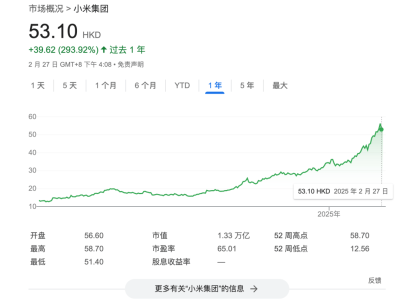
在AI领域,一个名为DeepSeek的创新企业正迅速崛起,其最新发布的DeepSeek-V3大语言模型引发了国内外广泛关注。与此同时,DeepSeek背后的“天才少女”罗福莉也成为了众人瞩目的焦点。
DeepSeek-V3的发布,标志着DeepSeek在AI大模型研发方面取得了重大突破。据技术报告显示,该模型的参数量高达671B,激活参数为37B,使用的预训练token量更是达到了14.8万亿。在多项评测中,DeepSeek-V3的表现超越了阿里的Qwen2.5-72B和meta的Llama-3.1-405B等其他开源模型,甚至在性能上与顶尖的闭源模型如GPT-4和Claude-3.5-Sonnet不相上下。
尤为引人注目的是,DeepSeek-V3在训练效率和成本方面展现出了极高的性价比。据DeepSeek官方透露,整个训练过程仅用了不到280万GPU小时,相比之下,meta旗下的Llama-3405B模型则耗费了3080万GPU小时。如果以H800的租金为每GPU小时2美元来计算,DeepSeek-V3的总训练成本仅为600万美元左右,仅为Llama-3405B训练成本的十分之一。
而DeepSeek之所以能够在性价比方面取得如此优异的成绩,与其背后的技术创新密不可分。DeepSeek专注于开发先进的大语言模型和相关技术,通过创新的架构和算法,实现了更高效的训练和推理。例如,在DeepSeek-V2中,他们就采用了MLA(多头潜在注意力)和前馈网络方面的DeepSeekMoE架构等创新技术,从而在保证性能的同时降低了成本。
DeepSeek的创始人梁文锋,是一位毕业于浙江大学电子工程系的80后技术专家。他始终保持着低调的作风,和所有研究员一样,每天沉浸在“看论文、写代码、参与小组讨论”的工作中。正是这样的专注和投入,让DeepSeek在短时间内取得了如此显著的成果。
除了技术创新和性价比优势外,DeepSeek还以其开源和免费商用的特点赢得了市场的青睐。早在半年前发布的DeepSeek-V2,就因性能达到GPT-4级别但价格仅为GPT-4-Turbo的百分之一而引发了业内关注。这一举措不仅降低了用户的使用成本,也推动了AI技术的普及和应用。
而在DeepSeek-V3爆火之后,背后的“天才少女”罗福莉也进入了人们的视野。据媒体报道,小米创始人雷军以千万年薪招揽了这位DeepSeek开源大模型的关键开发者之一,让她领导小米AI大模型团队。罗福莉本科就读于北京师范大学计算机专业,硕士毕业于北京大学计算语言学专业。她在学术方面有着深厚的造诣和丰富的经验,曾在人工智能领域顶级国际会议ACL上发表多篇论文。
罗福莉的加入,无疑为小米在AI大模型领域的发展注入了新的活力。小米近年来在AI领域持续发力,不仅组建了AI实验室大模型团队,还成立了专门的AI平台部,由元老级技术大牛张铎负责。他们正在不断提升算力储备和技术优势,以开放的态度与合作伙伴开拓更多机会。
对于小米而言,如何在烧钱的大模型业务中平衡成本,无疑是雷军考虑的核心问题。而罗福莉拥有DeepSeek-V2的研发背景,无疑为小米在成本控制和性能优化方面提供了宝贵的经验和支持。她的加入,将助力小米在AI大模型领域取得更加显著的成果。