随着国内AI大模型市场的逐步演进,一场从“百模大战”到淘汰整合的转变正在上演。历经2023年的资本狂热与行业激战,市场格局已初现端倪,昔日的百家争鸣如今已演变为新老巨头与新晋独角兽的两大阵营对垒。
在这场技术与商业化的较量中,以百度、字节跳动、阿里巴巴和腾讯为代表的老牌互联网巨头及“新BAT”阵营,凭借深厚的技术积累与商业化经验,抢占了先机。与此同时,以字节跳动、阿里巴巴、阶跃星辰、智谱AI和DeepSeek等组成的“基模五强”也全线发力,展开了激烈的技术与市场竞争。
字节跳动凭借“大模型家族”如豆包系列模型,在多模态理解与生成上不断取得突破。豆包通用模型(Doubao-Pro)在公开评测中已与GPT-4系列比肩,同时针对不同应用场景持续优化模型结构,推出了视觉理解模型和一系列专用模型,在语言、视觉、声音等多模态任务上保持领先。字节跳动的AI商业化投入巨大,豆包系列已在公司内部50多个业务场景中大规模上线,日调用量突破4万亿tokens。为了抢占市场,字节还大胆降价,推出了“厘时代”,豆包通用模型的定价远低于行业均价,这一轮降价风暴迅速提升了其市场份额。
阿里巴巴作为开源最早、最完整的大公司之一,在AI领域的投入同样坚决。通义团队已累积开源200多款模型,涵盖了千问大语言模型和万相视觉生成模型两大基座系列。最新发布的Qwen3系列模型在性能和多模态推理上有显著提升,同时选择将模型完全开源。阿里云服务端也积极降价抢市场,多款大模型推理价格大幅降低,通过开放模式与巨额补贴双管齐下,吸引全球开发者关注。
腾讯在大模型领域的战略部署同样持续进化。腾讯对其混元大模型研发体系进行了全面重构,加码研发投入,成立了专门的大语言模型部和多模态模型部,持续迭代基础模型,提升模型能力。腾讯自研的混元模型多模态性能强劲,已深度嵌入微信、QQ等产品,提高了用户端的智能化体验,同时通过腾讯云向外输出能力。
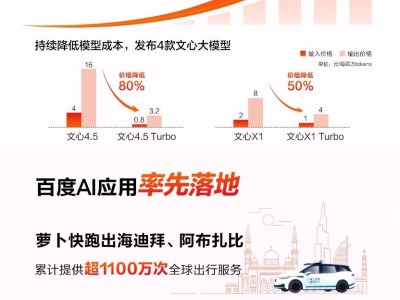
百度则持续加码大模型研发与开源,以“文心大模型”4.5系列为核心,推出并免费开放了ERNIE 4.5和深度思考X1,性能全面超越同级竞品。市场应用层面,文心一言平台全面免费后,用户规模迅速攀升,日均调用量突破15亿次。百度已将大模型能力深植搜索与智能助手,通过开放API吸引开发者创新。
除了“新老BAT”外,一些大模型初创企业同样展开全面进攻。阶跃星辰作为新兴力量,今年来动作频频,完成了数亿美元的B轮融资,融资将继续用于核心大模型的研发,特别是强化多模态和复杂推理能力。阶跃星辰已开源发布了多款多模态模型,在迭代了多个模型后跻身“AI六小虎”行列。智谱AI则专注认知智能大模型研发,与学术机构合作打造了中英双语千亿参数预训练模型,推出了对话模型ChatGLM及其开源版本,已成为国内首家进入IPO流程的大模型创业公司。
DeepSeek团队低调但技术打法极具冲击力,专注于语言模型尤其是数理逻辑能力,秉持坚定的开源策略。其发布的DeepSeek-R1模型以远低于常规的算力投入实现了与顶级模型媲美的性能,一度被忽视的DeepSeek一经开源便引爆关注。这些新兴主力在技术研发、人才储备、资金投入和市场开拓上全面发力,推动着AI技术不断向前发展。
然而,与此同时,“AI六小龙”这些曾被寄予厚望的创业小企业则出现了明显分化。以李开复创办的零一万物为例,公司大幅调整方向,主动与阿里云合作成立“产业大模型联合实验室”,将预训练算法团队和基础设施团队交给阿里,专心做小参数高性价比模型。零一万物开始放弃自行训练万亿参数模型,转向针对电商直播、会议等场景的行业智能应用。百川智能也显示出战略调整迹象,虽然依然获得资金支撑,但内部正在精简业务以求聚焦。月之暗面近期明显收紧打法,缩减烧钱战略,将资源集中在核心产品上。MiniMax则逐渐淡出同质化严重的情感陪聊红海,转而将资源向视频生成、音乐创作等更具技术壁垒的领域倾斜。
总体来看,当前中国AI“大模型”赛道的竞争格局已初步形成,以字节跳动、阿里巴巴、腾讯为代表的新BAT,以及阶跃星辰、智谱AI、DeepSeek等新兴主力构成了进攻重兵。他们在技术研发、市场开拓上全面发力,推动着AI技术不断向世界前沿靠近。在这种格局下,大公司的优势在于资源与生态整合,而创业公司则更强调创新与专注,各有千秋。而“AI六小龙”的走势虽有显著差异,但并非败退,而是行业成熟期必然的理性回调,目标是在巨头夹缝中守住“小而美”的生存空间。