论文*A Review of DeepSeek Models’ Key Innovative Techniques*介绍了开源大语言模型DeepSeek-V3和DeepSeek-R1背后的关键创新技术,涵盖架构优化、训练算法改进等多个方面,这些技术提升了模型性能和训练效率,同时指出了研究中的开放性问题与未来方向。
1. 模型概述与研究背景:ChatGPT开启大语言模型(LLM)新时代,专有模型表现卓越,开源模型与之仍有差距。2025年1月,DeepSeek的DeepSeek-V3和DeepSeek-R1模型表现突出,性能可与顶尖专有模型媲美,且训练成本低。剖析其技术对推动LLM研究意义重大。
2. 关键创新技术
多头潜在注意力(MLA):为解决长文本KV缓存瓶颈问题,DeepSeek-V2提出MLA。通过低秩键值联合压缩,减少KV缓存占用;采用解耦旋转位置嵌入,提升计算效率。MLA在减少缓存的同时性能优于标准多头注意力机制,但解耦旋转位置嵌入有待进一步研究。
专家混合(MoE):DeepSeekMoE架构创新地引入细粒度专家分割和共享专家隔离技术。前者提高激活专家组合灵活性,后者减少参数冗余。同时,通过辅助损失和无辅助损失的负载均衡策略,解决负载不均衡问题,但现有负载均衡损失函数的理论依据及改进方向值得探讨。
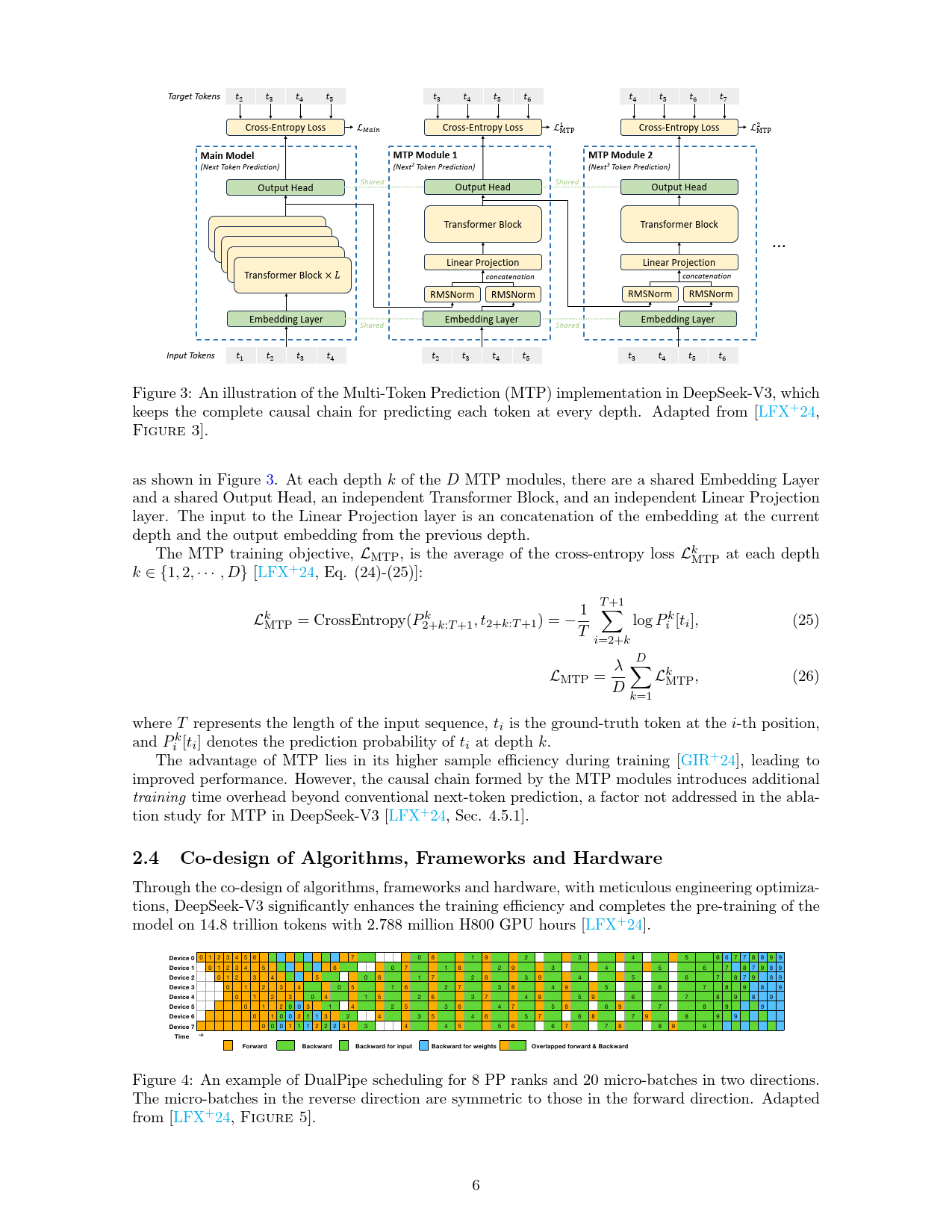
多令牌预测(MTP):DeepSeek-V3的MTP技术在训练时预测多个后续令牌,提升样本效率。但由于因果链的引入,训练时间会比传统单令牌预测更长,该问题在消融研究中未涉及。
算法、框架和硬件协同设计:DeepSeek-V3通过协同设计提升训练效率。DualPipe算法减少跨节点专家并行通信开销,采用双向流水线调度,但存在额外内存消耗问题。FP8混合精度训练框架在不降低精度的前提下加速训练,对特定算子保持原精度,并采用细粒度量化策略扩展FP8动态范围。
组相对策略优化(GRPO):GRPO是近端策略优化(PPO)的变体,在LLM训练中,它直接估计优势,避免训练价值函数,减少内存使用,且性能与PPO相当,效率更高。
后训练:基于基础模型的强化学习:DeepSeek-R1-Zero在基础模型上采用纯强化学习训练,展现出模型通过强化学习学习和泛化的能力,但存在可读性差和语言混合等问题。DeepSeek-R1则采用监督微调(SFT)和强化学习交替的迭代训练方法,并通过冷启动、推理导向的强化学习、拒绝采样和SFT、RL对齐四个阶段优化模型。
3. 研究讨论与未来方向:Transformer架构改进方面,对解耦旋转位置嵌入的深入研究和负载均衡目标的理论证明有重要意义;多令牌预测在提高样本效率的同时,训练时间优化仍有空间;算法、框架和硬件协同设计体现了整体设计的价值,DualPipe算法的改进值得关注;强化学习在模型后训练阶段表现出色,迭代训练方法和GRPO算法为研究开辟了新方向。
4. 研究结论:DeepSeek模型的成功得益于在Transformer架构、样本效率提升、算法框架硬件协同设计、强化学习算法及后训练应用等方面的创新。研究也指出了当前存在的开放性问题,为未来LLM研究提供了潜在方向 。