英伟达创始人兼CEO黄仁勋即将迎来一个至关重要的时刻,他将在英伟达年度技术峰会GTC上,为公司的股价重振带来希望。此次峰会上,黄仁勋将分享他引领英伟达探索AI新前沿的战略蓝图。
据此前摩根大通的分析预测,英伟达有望在大会上推出Blackwell Ultra芯片(GB300),并可能揭开Rubin平台的神秘面纱。本次大会的焦点将集中在AI硬件的全面革新上,包括性能更强劲的GPU、HBM内存、优化的散热和电源管理系统,以及CPO(共封装光学)技术的未来规划。
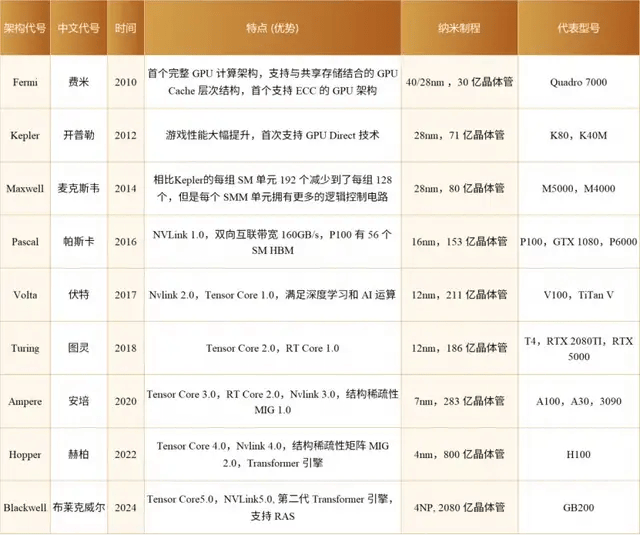
在黄仁勋发表演讲之前,让我们回顾一下英伟达近年来推出的系列架构,以及它们背后的精彩故事。
1999年末,英伟达推出了首款GPU(图形处理单元)Geforce 256,这款革命性的产品将完整的渲染管线集成至硬件中,为用户带来了显著的加速效果。然而,当时它还未具备可编程能力,直到2001年随着DX8引入可编程顶点着色器的概念,英伟达在Geforce 3中加入了Vertex Processor,GPU才迎来了可编程的新纪元。随后,DX和OpenGL不断引入更多可编程着色器,以满足渲染开发者的多样化算法需求。
GPU的最初设计目标是图形加速,而非深度学习。在CUDA架构问世之前,GPU对深度学习运算的支持相对有限。真正用于人工智能算力支持的并非普通显卡,而是GPGPU(通用计算图形处理器),这种算力单元能够处理非特定需求的计算任务。
CUDA架构的诞生,标志着GPU并行计算革命的开始。随着GPU可编程能力的发掘,越来越多的大学和研究机构开始尝试用GPU进行科学计算。2003年的SIGGRAPH大会上,众多业界权威发表了关于GPU运算的设想和实验模型,GPGPU的研讨交流也成为会议的重要议题。然而,当时的开发者只能利用着色器编程语言开发程序,计算资源的映射和使用过程繁琐复杂。因此,急需一种专为GPU并行计算设计的编程语言。正是在这种背景下,斯坦福大学的Ian Bark投身到Brook(后被AMD收购)的研发中,成为GPU并行计算软件栈的先驱。2004年,他以实习生的身份加入英伟达,并在两年后成功开发出CUDA。
随着渲染需求的多样化,并行计算业务也蓄势待发。在这样的历史背景下,英伟达推出了Tesla G80架构,这成为英伟达命运的重要转折点。2006年,英伟达推出了Tesla架构的第一代产品G80,开启了GPU通用计算的探索之路。G80采用全新的CUDA架构,支持C语言进行GPU编程,实现了通用数据并行计算。G80不仅是有史以来最伟大的GPU变革产物之一,更开启了并行加速的新时代。随后,英伟达在第一代基础上推出了Tesla架构的第二代产品GT200,其双精度FMA运算速度提升了8倍多。
在G80和GT200两代产品上,英伟达积累了大量用户体验反馈,并招募了Bill Dally作为首席科学家。最终,英伟达推出了划时代的Fermi架构,这是首款专门为计算任务设计的GPU。Fermi架构不仅重新定义了GPU的概念,更在加速并行计算性能的同时,保持了强大的图形渲染能力。GF100是首款基于Fermi架构的GPU,集成了32亿个晶体管,专为下一代游戏和通用计算应用程序而优化。
随后,英伟达保持了大约两年更新一次架构的频率,不断推陈出新。2012年,英伟达推出了Kepler架构,这是首个支持超级计算和双精度计算的GPU架构。Kepler在性能和功耗方面实现了显著提升,成为高性能计算的焦点。2014年,英伟达发布的Maxwell架构是Kepler架构的升级版,采用台积电28nm工艺制程,专为低功耗、高性能GPU需求大增的移动设备而设计。
2016年,Pascal架构推出,用于接替Maxwell架构。Pascal架构是首个为了深度学习而设计的GPU,支持所有主流的深度学习计算框架。Pascal架构的核心阵容强大,包括GP100和GP102两大核心。随后,英伟达推出了专门针对神经网络加速的Volta架构,引入了Tensor Core(张量核心)专门加速矩阵运算,提升深度学习计算效率。Volta的出现标志着AI成为GPU发展的新方向。
2018年,英伟达发布了Turing架构,进一步增强了Tensor Core的功能,并新增了对整数格式的支持,将GPU的性能吞吐量推向新高度。同时,Turing架构还引入了先进的光线追踪技术,代表了图形技术的新突破。2020年,Ampere架构的推出再次刷新了人们对Tensor Core的认知,新增了对TF32和BF16两种数据格式的支持,并引入了对稀疏矩阵计算的支持,大幅提升计算效率并降低能耗。
英伟达在AI时代的全面引领也体现在其产品的广泛应用上。2016年,黄仁勋将第一台DGX-1超级计算机赠予OpenAI。而在2022年年底,OpenAI发布的ChatGPT生成式大语言模型成为深度学习发展历程中的里程碑。在这波AI革命中,英伟达作为“卖铲人”,发布了H100 GPU,凭借最新的Hopper架构,H100成为地表最强并行处理器。Hopper架构标志性的变化是新一代流式多处理器的FP8张量核心,进一步加速了AI训练和推理过程。
同时,NVIDIA Grace Hopper超级芯片将Hopper GPU的突破性性能与Grace CPU的多功能性结合在一起,通过高带宽和内存一致的NVLink Chip-2-Chip(C2C)互连,以及新的NVLink切换系统,解决了CPU和GPU之间数据的时延问题,成为高性能计算(HPC)和AI工作负载的异构加速平台。2024年,英伟达推出的Blackwell架构为生成式AI带来了显著飞跃,GB200超级芯片在处理LLM推理任务时性能提升了30倍,同时在能耗方面也优化了25倍。
英伟达GPU架构的每一次重大创新和升级,都在推动深度学习技术的边界。这些架构的发展不仅体现了英伟达在硬件设计方面的前瞻性,也为深度学习的研究和应用提供了强大的计算支持,加速了AI技术的快速发展。