在设计集成电路时,工程师的目标是生产出更容易制造的高效设计。如果他们设法降低电路尺寸,那么制造该电路的经济性也会下降。英伟达公司在其技术博客上发布了一项技术,该公司使用一种名为PrefixRL的人工智能模型。利用深度强化学习,英伟达公司使用PrefixRL模型来超越主要供应商的传统EDA(电子设计自动化)工具,如Cadence、Synopsys或Siemens/Mentor。
EDA供应商通常会在内部实施人工智能解决方案,以实现硅片放置和路由(PnR);然而,英伟达的PrefixRL解决方案似乎在该公司的工作流程中创造了奇迹。
创建一个深度强化学习模型,旨在保持与EDA PnR尝试相同的延迟,同时实现更小的芯片面积,这是PrefixRL的目标。
根据NVIDIA技术博客介绍,最新的Hopper H100 GPU架构使用了PrefixRL AI模型设计的13000个算术电路实例。英伟达制作的模型输出的电路比同类EDA输出的电路小25%。这一切都在实现类似或更好的延迟。下面你可以在图中比较PrefixRL制作的64位加法器设计和一个业界领先的EDA工具制作的相同设计:

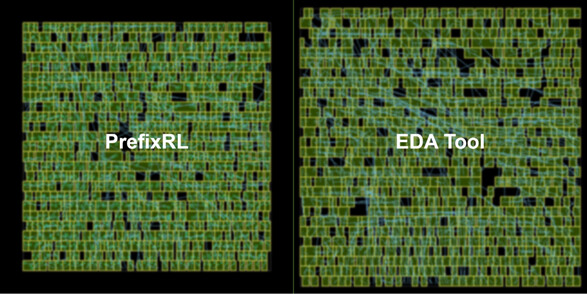
训练这样一个模型是一项计算密集型的任务。英伟达公司报告说,设计一个64位加法器电路的训练,每个GPU需要256个CPU核心和32000个GPU小时。该公司开发了Raptor,这是一个内部分布式强化学习平台,利用英伟达硬件的独特优势进行这种工业强化学习,你可以看到下面的内容以及它的操作方式:

总的来说,该系统相当复杂,需要大量的硬件和投入;然而,回报是更小、更高效的GPU。